◆ k-means 클래스
- 보통의 비지도 학습에서 사과, 바나나, 파인애플과 같이 클래스를 알 수 없음
- 이 방법을 해결하기 위해 가까운 샘플과 평균값을 비교한 알고리즘인 k-means를 사용함
- 거리기반 분류법
◆ 데이터 로드
◆ k-means 훈련
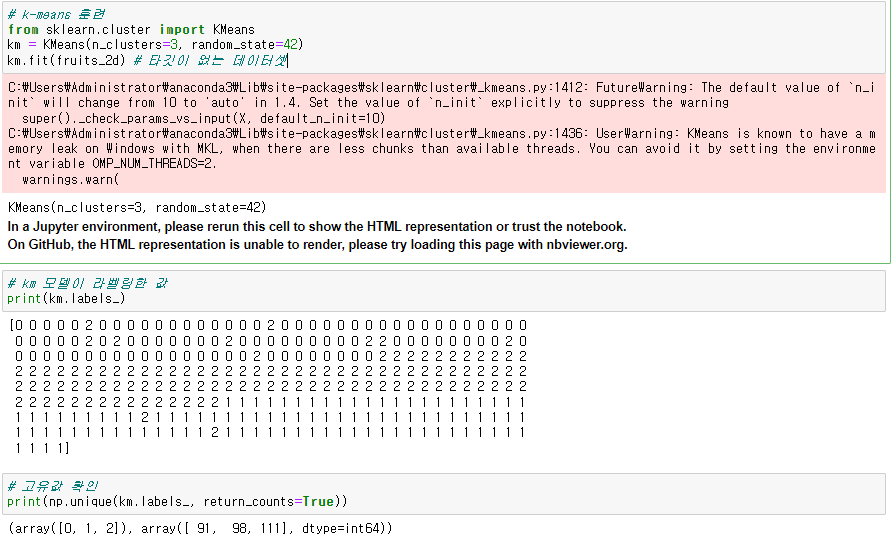
from sklearn.cluster import KMeans
km = KMeans(n_clusters= , random_state= )
km.fit(data)
● 라벨링 값
km.labels_
● numpy 고유값 확인
np.unique(데이터, return_counts=True) # return_counts=True : 고유값 개수 출력
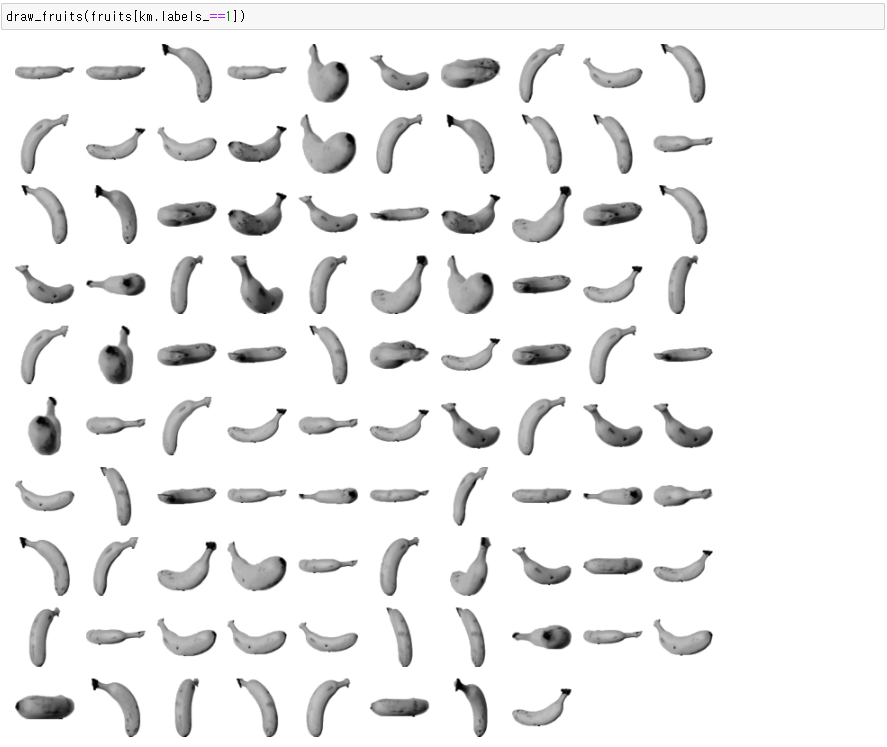
◆ 분류 후 이미지 그리기
● 그리는 함수 정의

● 분류한대로 그리기


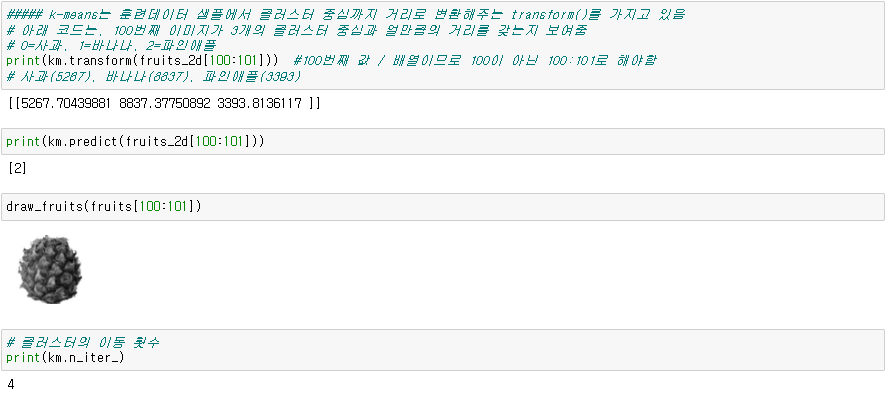
● 클러스터의 중심
km.cluster_centers_ : 분류하는 기준
# ratio : 이미지 크기
km.transform() : 각 분류하는 기준과 해당 데이터와의 거리
km.n_iter_ : 중심이 이동한 횟수

◆ 최적의 k값 찾기
- k-means의 가장 큰 단점 중 하나는 클러스터 갯수를 사전에 하이퍼파라미터로 지정하애함
- 실전에서는 클래스의 갯수가 몇개인지 모름
- 따라서 이 k값(n_clusters)을 설정할 수 없기 땜누에, 이너셔 알고리즘 중 엘보우 방법을 대표적으로 사용함
- 이너셔란 클러스터에 속한 샘플이 얼마나 조밀하게 모여있는지를 나타내는 값
- k값이 많아지면 당연히 어너셔가 작아짐
- 급격하게 꺽이는 부분이 최적값 -> 엘보우 솔루션


'데이터 분석' 카테고리의 다른 글
| 공공데이터 프로젝트 : 고용불안의 원인 분석과 고찰 및 미치는 영향분석 (0) | 2024.01.21 |
|---|---|
| PCA(주성분분석) (0) | 2023.12.18 |
| Clustering(군집 분석) (0) | 2023.12.18 |
| Ensemble(앙상블)(RandomForest, GB, HGB, XGB, LGBM) (0) | 2023.12.13 |
| Cross_Validation(교차검증) & GridSearchCV (0) | 2023.12.13 |



