◆ 교자검증과 그리드 서치
- 훈련셋으로훈련하고, 테스트셋으로 테스트하면서 과대, 과소적합 해결과 편향을 줄일 수 있음
- 하지만, 지속적인 테스트셋의 결과로 인한 수정은, 결국 테스트셋에 잘 맞는 모델이 만들어짐
◆ Train Test split(홀드아웃)
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train, target, test_size= )

◆ 교차검증
- 기본값 : 5
- 데이터를 나누어 검증셋을 돌아가면서 선택하며 학습 및 검증을 진행
from sklearn.model_selection import cross_validate
cross_validate(model, train, target)
● StratifiedKFold
- 타겟이 분류문제일경우 StratifiedKFold를 사용
- 분류문제일 경우 편향이 있을 수 있어 이를 맞추기위해
- 하지만 cross_validate를 사용할때 target이 분류일경우 자동으로 StratifiedKFold가 들어가므로 안해줘도 무관
- 세부 설정을 하기위해서 라이브러리 이용
from sklearn.model_selection import StratifiedKFold
cross_validate(model, train, target, cv=StratifiedKFold(n_splits= , shuffle= )) # n_splits : 폴드 수 / shuffle : 셔플 여부

◆ GridSearchCV(하이퍼 파라미터 튜닝)
- 모델이 학습한 파라미터 = 모델 파라미터(coef_, intercept_ 등)
- 모델이 직접 설정할 수 없어 개발자가 지정하는 파라미터 = 하이퍼 파라미터
- 그리드 서치를 하면 자동으로 cross_validate를 실행함(default=5)
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease' : [0.0001, 0.0002, 0.0003, 0.0004, 0.0005],
파라미터2 : [ ],
파라미터3 : [ ] }
gs = GridSearchCV(model, params, n_jobs=-1) # n_jobs : (CPU)코어 / -1 : 전부
gs.fit()
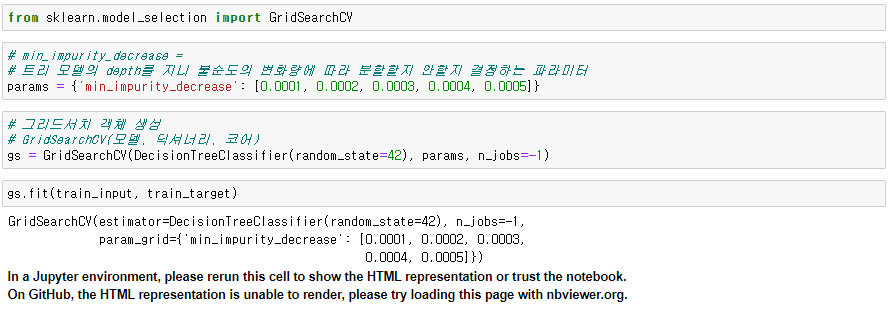
● 속성
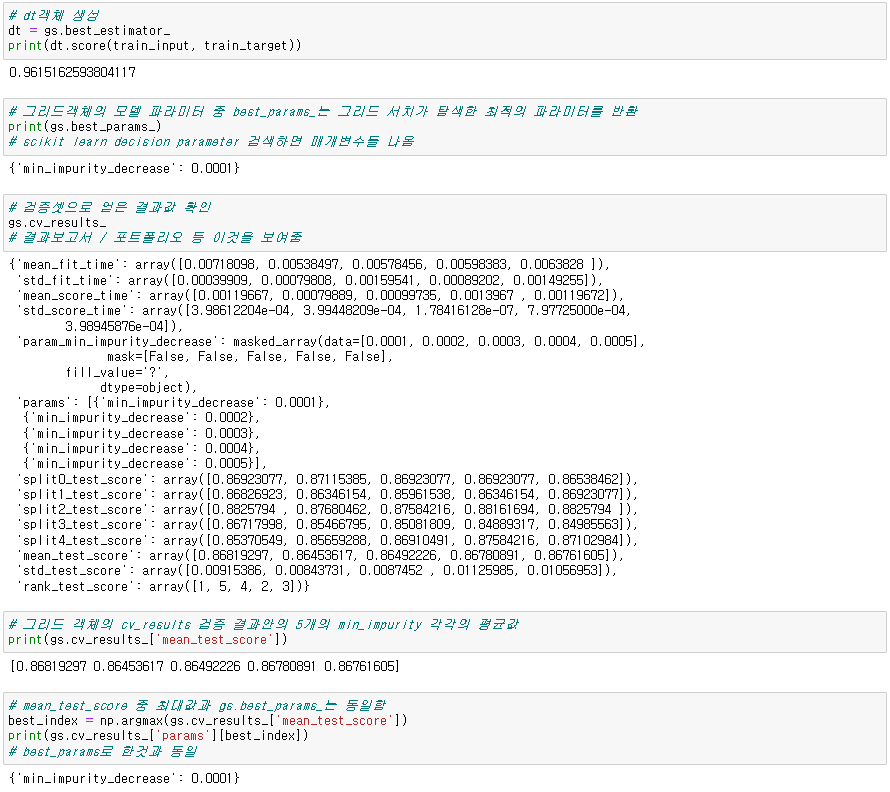
dt = gs.best_estimator_ # gs 객체를 최상의 파라미터로 설정하여 dt객체 생성(model 객체 생성)
(dt = DecisionTreeClassifier()에서 파라미터를 최상으로 넘기는 것과 같음)
gs.best_params_ # gs객체의 모델 파라미터 중 최상 파라미터를 반환
# 인터넷에 sckit learn decision tree parameter를 검색하여 sckit-learn 홈페이지에서 파라미터를 확인 가능
gs.cv_results_ # 결과보고서 작성시 파라미터를 설정한 근거로서 첨부
gs.cv_results_['mean_test_score'] # 인덱스로 원하는 결과만 출력 가능
● 여러개의 파라미터 설정
- 나중에 파라미터 추가 및 수정시 딕셔너리를 바꾼 후 다시 돌려야함(후에 따로 추가 및 변경 불가능)

◆ 랜덤 서치
● 랜덤 파라미터 설정
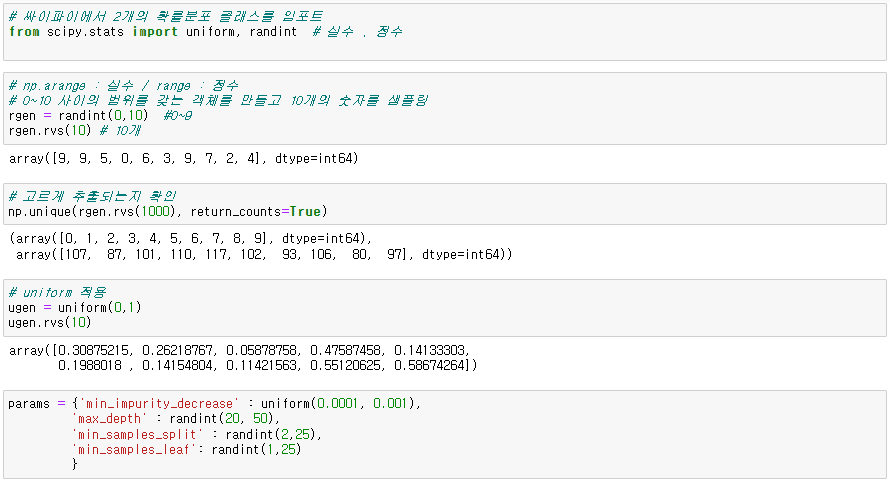
from scipy.stats import uniform, randint # uniform : 실수범위 중 랜덤한 수, randint : 정수범위 중 랜덤한 수
# np.arange : 실수, range : 정수
rgen = randint(0,10) # 0~10
rgen.rvs(10) # 10개
ugen = uniform(0,1) # 0~1
ugen.rvs(10) # 10개
● 모델 적용
from sklearn.model_selection import RandomizedSearchCV
RandomizedSearchCV(model, params, n_iter= , n_jobs= )
# n_iter : 랜덤한 수를 몇번 할지 / 모델을 얼마나 반복할지 / 위의 rvs와 동일

'데이터 분석' 카테고리의 다른 글
| Clustering(군집 분석) (0) | 2023.12.18 |
|---|---|
| Ensemble(앙상블)(RandomForest, GB, HGB, XGB, LGBM) (0) | 2023.12.13 |
| Decision_Tree(의사결정나무) (0) | 2023.12.12 |
| Stochastic Gradient Descent(SGD, 확률적 경사 하강법) (0) | 2023.12.12 |
| Logistic_regression (0) | 2023.12.12 |



