
Input Layer ----> Hidden Layer ------> Output Layer
^ 가중치 ^ sigmoid or relu ^ softmax
◆ 임포트
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinisim() -> 모델의 일관성 보장

◆ 2개 층 설정
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data() # 내장데이터 로드
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0 # 이미지 데이터의 픽셀값을 0~1사이로 만들어 훈련을 더 효과적이게함
train_scaled = train_scaled.reshape(-1, 28*28) # (샘플수,28,28) -> (샘플수,784) 로 변환 => 평탄화
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)

● 히든 레이어 설정
딥러닝 절차
1) 층의 규칙(형태) 설정
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)) # 784 : 28*28
desne2 = keras.layersDense(10, activation='softmax')

2) 층의 규칙이 적용된 모델 생성
- 리스트 형태로 Sequential 함수에 dense 넘김
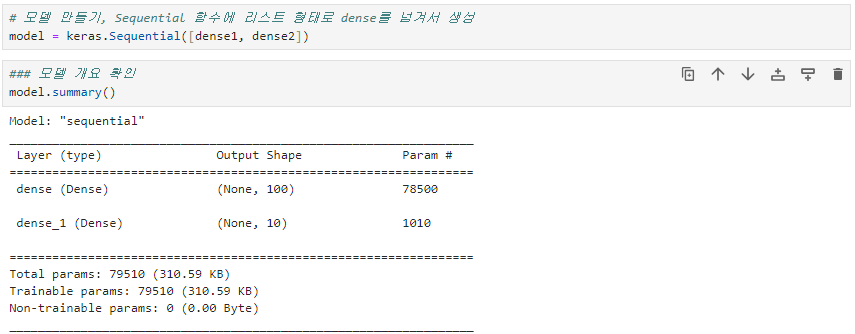
model = keras.Sequential([dense1, dense2]) # dense1 : hidden layer, dense2 : output layer
model.summary() # 모델 개요 확인
* Param : 그림에서 선(다음 층의 노드와 연결하는 선)의 수(784*100 + 100) - 마지막 +100 : 노드에 붙는 activation function(활성함수)
※ 다른 방법
model = keras.Sequenctial([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')

※ 만들어진 모델에 층을 추가하는 방법(가장 많이 사용됨)
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))

3) 옵티마이저(컴파일러)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')

4) 훈련
model.fit(train_scaled, train_target, epochs=5)

◆ ReLU 활성화 함수 적용
- 은닉층의 활성화함수로 relu가 가장 많이 사용됨
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
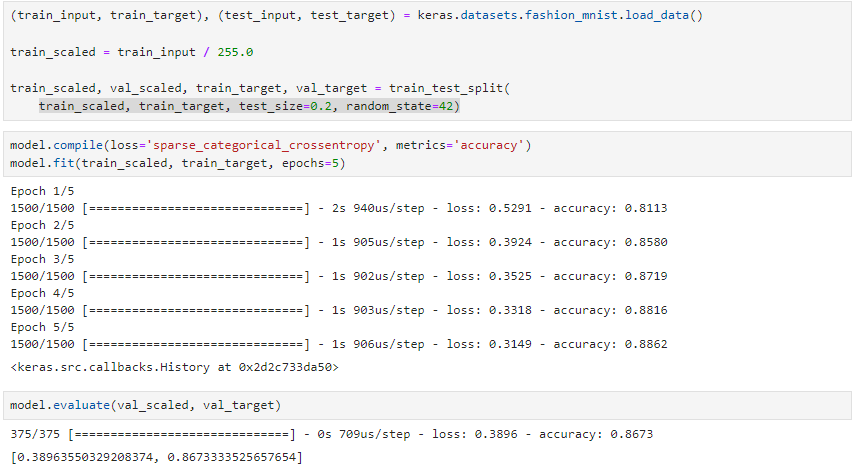
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)

◆ 옵티마이저
- 층을 넘어갈 때 최적화 하는 방법
- ex: SGD, AdaGrad, Adam
- 딥러닝의 손실률 계산 알고리즘인 옵티마이저는 학습속도를 이와같이 수동으로 세팅하여야 함
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True) # sklearn에서 sgd와는 다름
# momentum : 관성, 가속화 되는 부분에 가중치를 줘서 더 빠르게 / nesterov : 받아들이는 것, 빠르게
# 현업에서는 SGD 느려서 잘 안씀

- Adagrad는 수동으로 속도를 조절할 필요가 없는 최적화 알고리즘
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')
- Adam
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)

'데이터 분석' 카테고리의 다른 글
| CNN (Pytorch) (0) | 2024.06.30 |
|---|---|
| CNN 기초(Tensorflow, Keras) (0) | 2024.06.30 |
| DeepLearning(Tensorflow, Keras) (0) | 2024.02.20 |
| 공공데이터 프로젝트 : 고용불안의 원인 분석과 고찰 및 미치는 영향분석 (0) | 2024.01.21 |
| PCA(주성분분석) (0) | 2023.12.18 |



