● 임포트 및 데이터 준비
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor
train_data = datasets.MNIST(root = 'data', train = True, transform = ToTensor(), download = True)
test_data = datasets.MNIST(root = 'data', train = False, transform = ToTensor())
● 데이터 시각화
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.imshow(train_data.data[0], cmap='gray') # imshow : image show, 이미지 데이터를 화면에 출력
for i in range(train_data.data[0].shape[0]):
for j in range(train_data.data[0].shape[1]):
c = 1 if train_data.data[0][i, j].item() < 128 else 0
ax.text(j, i, str(train_data.data[0][i, j].item()), color=(c,c,c), ha='center', va='center', fontsize=5)
plt.title('%i' % train_data.targets[0]) # 포맷팅
plt.show()
figure = plt.figure(figsize=(10,8))
cols, rows = 5, 5
for i in range(1, cols * rows +1):
sample_idx = torch.randint(len(train_data), size=(1,)).item() # 랜덤숫자 선택 , = np.random.randint()와 동일한 효과
img, label = train_data[sample_idx]
figure.add_subplot(rows, cols, i) # rows, cols 그리드에 i번째 subplot 추가
plt.title(label)
plt.axis('off')
plt.imshow(img.squeeze(), cmap='gray')
plt.show()
◆ CNN Model
● 데이터 로더
from torch.utils.data import DataLoader
loaders = {
'train' : DataLoader(train_data, batch_size=100, shuffle=True, num_workers=1),
'test' : DataLoader(test_data, batch_size=100, shuffle=True, num_workers=1)
}
# batch_size : 지정된 크기의 배치로 나누어 로드
# shuffle : 데이터를 무작위로 섞음
# num_workers : n개의 수의 병렬 작업자를 사용하여 병렬처리 -> 로딩 속도 높임
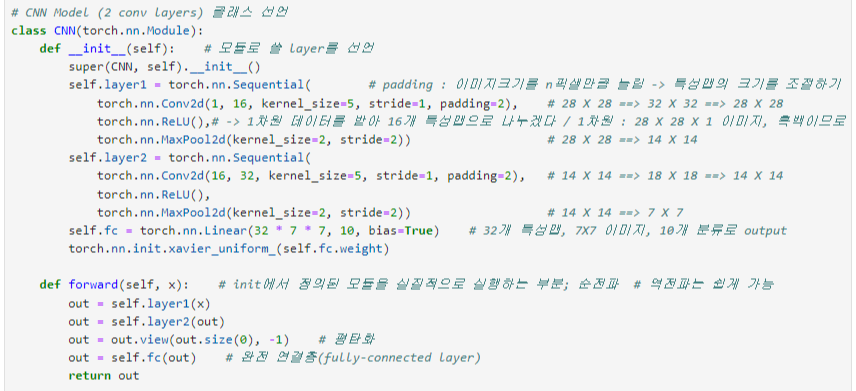
● CNN Model class 선언( 2 conv layers)
class CNN(torch.nn.Module):
def __init__(self): # 모듈로 쓸 layer를 선언
super(CNN, self).__init__()
self.layer1 = torch.nn.Sequential( # padding : 이미지크기를 n픽셀만큼 늘림 -> 특성맵 크기 조절
torch.nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), # 28 X 28 -> 32 X 32 -> 28 X 28
torch.nn.ReLU(), # -> 1차원 데이터를 받아 16개 특성맵으로 나누겠다 / 1차원(흑백) : 28 X 28 X 1 이미지
torch.nn.MaxPool2d(kernel_size=2, stride=2)) # 28 X 28 -> 14 X 14
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), # 14 X 14 -> 18 X 18 -> 14 X 14
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)) # 14 X 14 -> 7 X 7
self.fc = torch.nn.Linear(32 * 7 * 7, 10, bias=True) # 32개 특성맵, 7 X 7 이미지, 10개 분류로 output
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x): # init에서 정의된 모듈을 실질적으로 실행하는 부분; 순전파
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1) # 평탄화
out = self.fc(out) # 완전 연결층(fully-connected layer)
return out
model = CNN() # 인스턴스 생성

● 학습
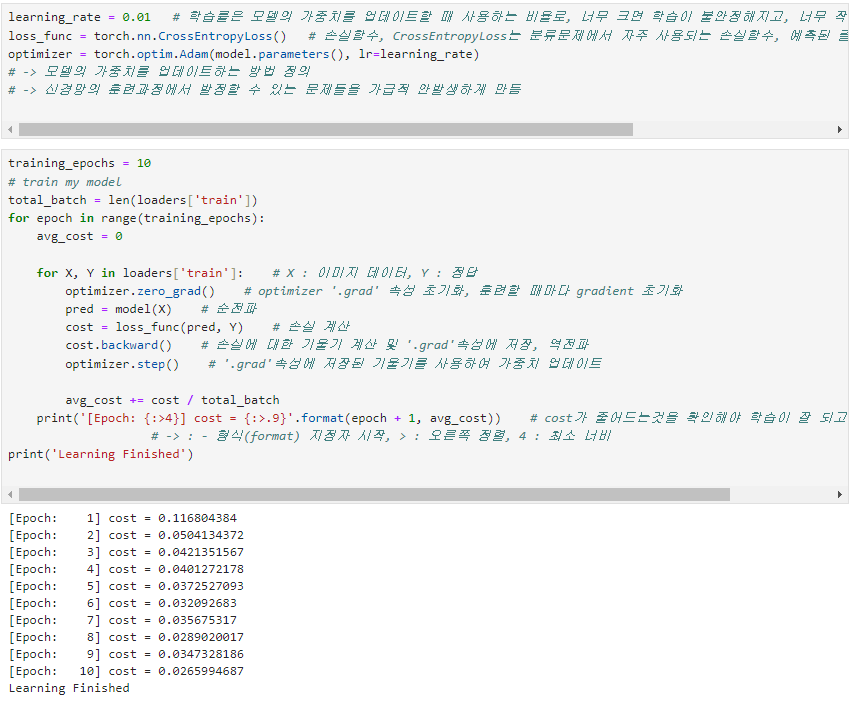
learning_rate = 0.01 # 학습률은 모델의 가중치 업데이트할 때 사용하는 비율, 너무 크면 불안정해지고 너무 작으면 학습 속도가 느려짐
loss_func = torch.nn.CrossEntropyLoss() # 손실함수, CrossEntropyLoss는 분류문제에서 자주 사용되는 손실함수, 예측된 클래스 확률과 실제 클래스 간의 차이 측정
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 모델의 가중치를 업데이트하는 방법 정의
# 신경망의 훈련과정에서 발생할 수 있는 문제들을 가급적 안발생하게 만듬
training_epochs = 10
total_batch = len(loaders['train'])
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in loaders['train']): # X : 이미지 데이터, Y : 정답
optimizer.zero_grad() # '.grad' 속성 초기화, 훈련할때마다 초기화 필요
pred = model(X) # 순전파
cost = loss_func(pred, Y) # 손실 계산
cost.backward() # 손실에 대한 기울기 계산 및 '.grad' 속성에 저장, 역전파
optimizer.step() # '.grad' 속성에 저장된 기울기를 사용하여 가중치 업데이트
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost)) # cost가 줄어드는 것을 확인해야 학습이 잘 되고있는지 알 수 있음
print('Learning Finished')
● 모델 평가
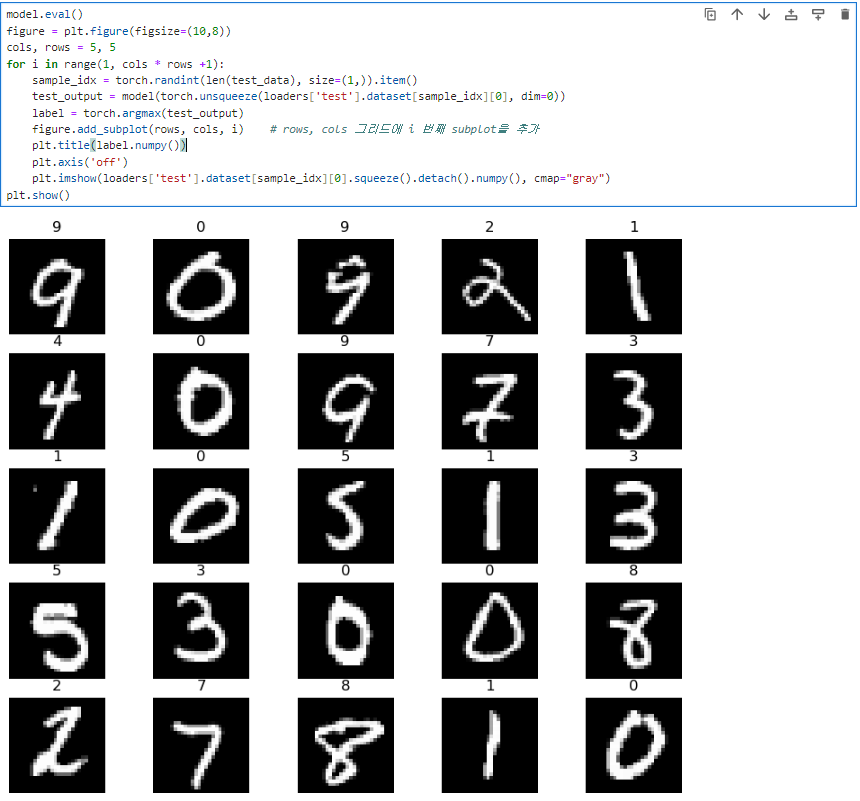
model.eval()
figrue = plt.figure(figsize=(10,8))
cols, rows = 5, 5
for i in range(1, cols * rows +1):
sample_idx = torch.randint(len(test_data), size=(1, )).item()
test_output = model(torch.unsqueeze(loaders['test'].dataset[sample_idx][0], dim=0))
label = torch.argmax(test_output)
figure.add_subplot(rows, cols, i)
plt.title(label.numpy())
plt.axis('off')
plt.imshow(loaders['test'].dataset[sample_idx][0].squeeze().detach().numpy(), cmap='gray')
plt.show()
'데이터 분석' 카테고리의 다른 글
| CNN 기초(Tensorflow, Keras) (0) | 2024.06.30 |
|---|---|
| DeepLearning_Depth(Tensorflow, Keras) (0) | 2024.06.30 |
| DeepLearning(Tensorflow, Keras) (0) | 2024.02.20 |
| 공공데이터 프로젝트 : 고용불안의 원인 분석과 고찰 및 미치는 영향분석 (0) | 2024.01.21 |
| PCA(주성분분석) (0) | 2023.12.18 |



