◆ 판다스 임포트
● 파이썬을 직접 사용할 때(모듈 임포트 에러 뜰경우)
- !pip install [라이브러리명]
● 라이브러리 임포트
- import [라이브러리명] as [약어]

◆ 시리즈(Series)
● 생성
[변수] = pd.Series([딕셔너리])

| index | 열 |
● 변환
1) 리스트 -> 시리즈
[변수] = pd.Series([리스트])
※ [시리즈].index = 인덱스 추출
[시리즈].values = 원소 값 추출

2) 튜플 -> 시리즈
[변수] = pd.Series([튜플])
[변수] = pd.Series([튜플], index=[인덱스1, 인덱스2, ... ]) -> 인덱스 이름 지정

● 원소 선택(인덱스, 슬라이싱)
▶ 인덱스
시리즈[인덱스 번호]
시리즈['인덱스 명']
▶ 슬라이싱
시리즈[인덱스 번호1 : 인덱스 번호2] -> 인덱스1
시리즈['인덱스 명1' : '인덱스 명2'] -> 인덱스1,인덱스2

◆ 데이터 프레임(DataFrame)
● 생성
[변수] = pd.DataFrame([딕셔너리])
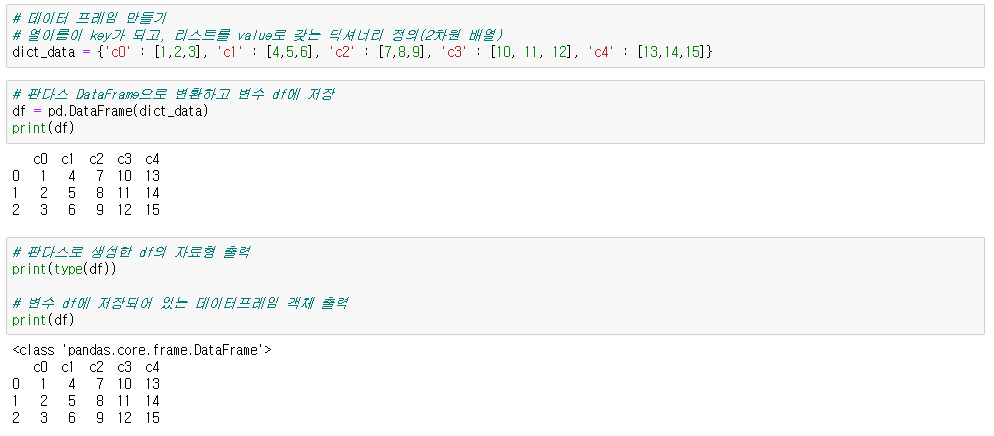
| index | 열1 | 열2 | 열3 |
● 리스트 데이터프레임 생성
pd.DataFrame([[리스트1], [리스트2], [리스트3]],
index=[인덱스명1, 인덱스명2, 인덱스명3],
columns=[컬럼명1, 컬럼명2, 컬럼명3])
| index | 컬럼명1 | 컬럼명2 | 컬럼명3 |
| 인덱스명1 | 리스트1[0] | 리스트1[1] | 리스트1[2] |
| 인덱스명2 | 리스트2[0] | 리스트2[1] | 리스트2[2] |
| 인덱스명3 | 리스트3[0] | 리스트3[1] | 리스트3[2] |

● 인덱스, 컬럼 이름 변경
df.index = ['index1', 'index2', 'index3']
df.columns = ['col1', 'col2', 'col3']
df.rename(index={'index1':'인덱스1', 'index2':'인덱스2', 'index3':'인덱스3'}, inplace=True)
df.rename(columns={'col1':'컬럼1', 'col2':'컬럼2', 'col3':'컬럼3'}, inplace=True)
※ 'inplace=True'를 사용하지 않으면 저장되지 않음

● 행, 열 삭제
1) 행 삭제
데이터프레임.drop(행, inplace=True)
데이터프레임.drop([행1, 행2], axis=0, inplace=True)
※ 'axis=0' - 행 (default)
'axis=1' - 열
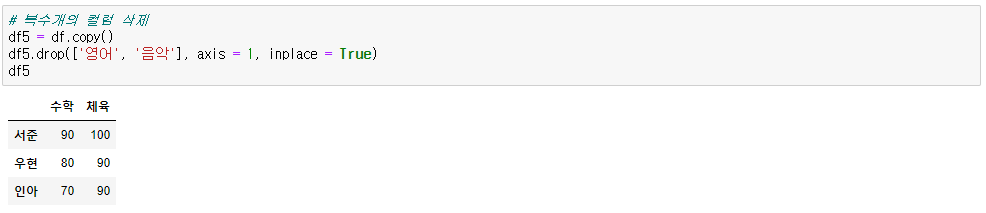
2) 열 삭제
데이터프레임.drop(열, axis=1, inplace=True)
데이터프레임.drop([열1, 열2], axis=1, inplace=True)

● 행, 열 선택
▶ 행 선택
1) loc
데이터프레임.loc[인덱스명] -> 시리즈
데이터프레임.loc[[행1, 행2, 행3]] -> 데이터프레임
데이터프레임.loc[행1:행3] -> 데이터프레임
2) iloc
데이터프레임.iloc[인덱스 번호] -> 시리즈
데이터프레임.iloc[[행번호1, 행번호2, 행번호3]] -> 데이터프레임
데이터프레임.iloc[행번호1 : 행번호3] -> 데이터프레임
▶ 열 선택
데이터프레임[컬럼명] -> 시리즈
데이터프레임.컬럼명
데이터프레임[[컬럼1, 컬럼2, 컬럼3]] -> 데이터프레임



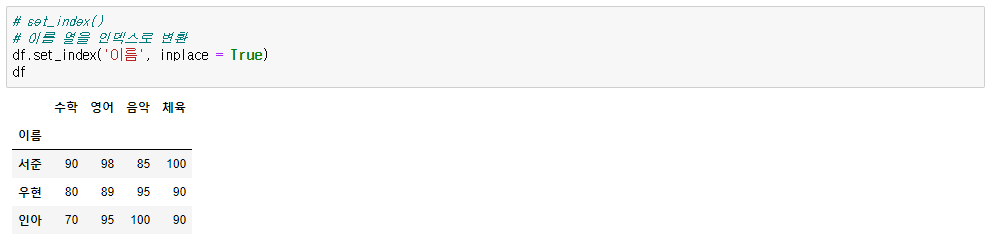
▶ 컬럼을 인덱스로 설정
데이터프레임.set_index(컬럼명, inplace=True)
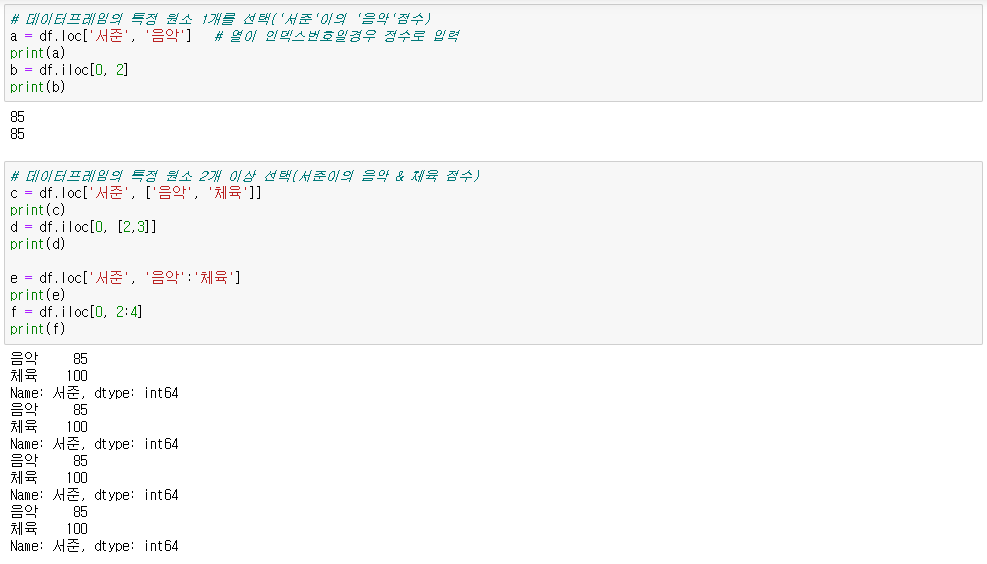
▶ 특정 원소 선택
1) 1개 선택
데이터프레임.loc['인덱스명', '컬럼명']
데이터프레임.iloc[인덱스번호, 컬럼번호]
2) 2개 이상 선택
데이터프레임.loc[['인덱스1', '인덱스2'], ['컬럼1', '컬럼2']]
데이터프레임.loc['인덱스1':'인덱스3', '컬럼1':'컬럼3']
데이터프레임.iloc[[인덱스번호1, 인덱스번호2], [컬럼번호1, 컬럼번호2]]
데이터프레임.iloc[인덱스번호1:인덱스번호3, 컬럼번호1:컬럼번호3]

'데이터 분석' 카테고리의 다른 글
| Matplotlib 그래프 & 그래프 세부설정 (라인그래프, 점그래프, 점&라인그래프, 면적그래프, 막대그래프), (스택 여부, 수평, 보조축) (0) | 2023.11.06 |
|---|---|
| Pandas Plot(판다스 그래프 그리기) (0) | 2023.10.31 |
| 데이터 분석 기초 (0) | 2023.10.31 |
| 판다스 데이터불러오기 (0) | 2023.10.31 |
| 판다스 기초 2 (0) | 2023.10.31 |



