◆ 데이터프레임
● 행, 열 추가
1) 컬럼(열) 추가
df[컬럼명] = 값

2) 행 추가
df.loc[행번호] = 값
df.loc[행번호] = [값1, 값2, 값3...]


● 원소 변경
df.loc[행이름, 열이름] = 값
df.loc[행이름][열이름] = 값
df.iloc[행번호, 열번호] = 값
* 복수선택 : 리스트 이용


● 행, 열 전치
df.transpose()
df.T

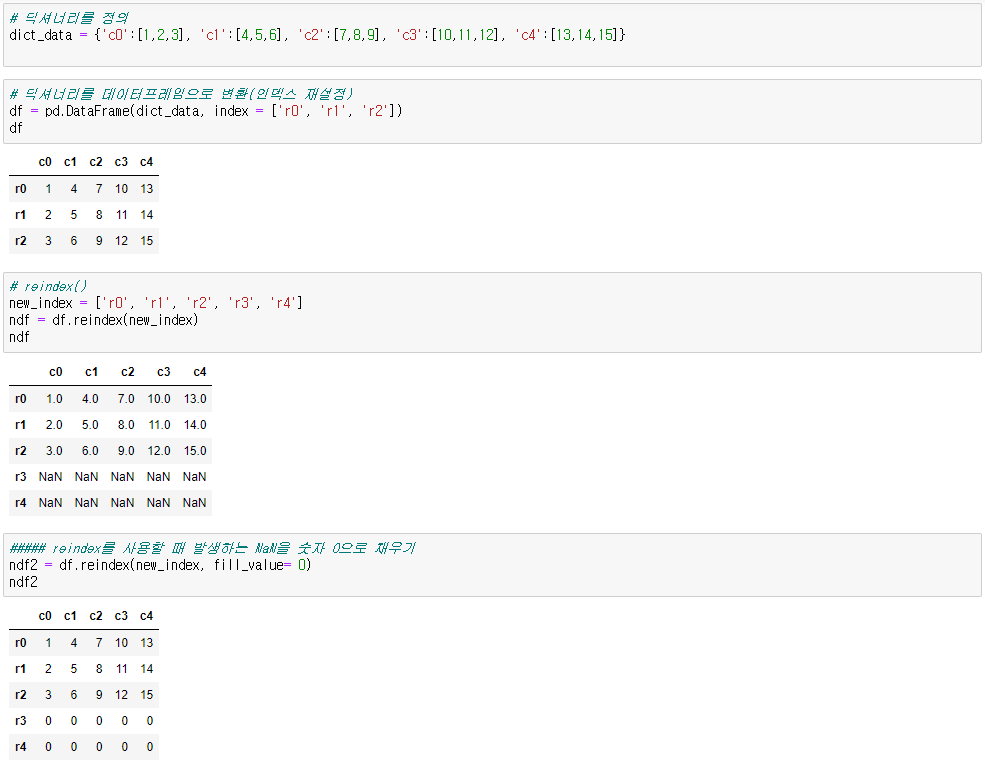
● 인덱스 재설정
df.reindex(인덱스명)
df.reindex([인덱스1, 인덱스2,...])
df.reindex(인덱스명, fill_value=값) # 추가되는 행을 값으로 채우기
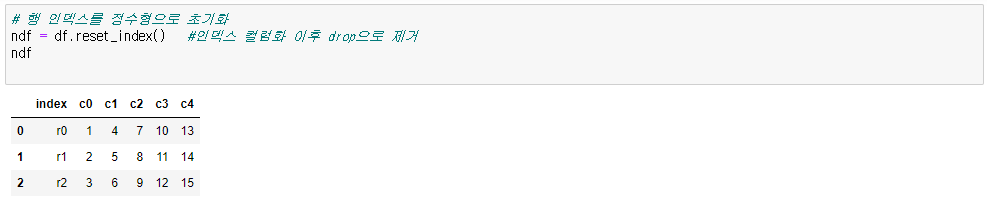
● 인덱스 초기화
df.reset_index()
df.reset_index(drop=true)
● 정렬(sort)
df.sort_index(ascending=False) # 인덱스 내림차순
df.sort_index(ascending=True) # 인덱스 오름차순
df.sort_values(by=컬럼명, ascending=False) # 해당 컬럼값을 기준으로 정렬

◆ 연산
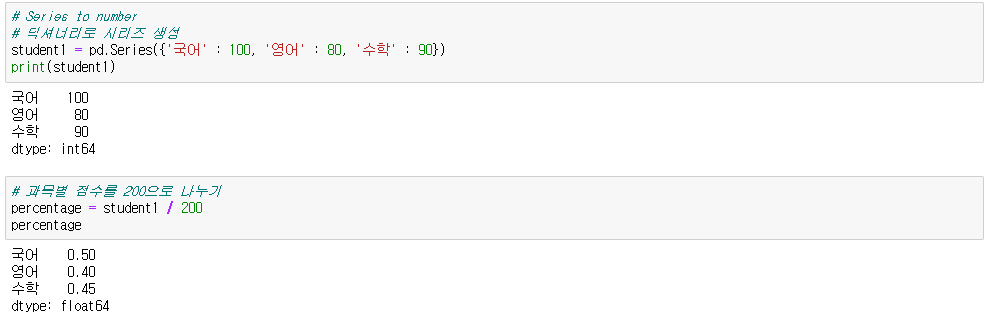
● Series to number
시리즈 + n(숫자)
시리즈 - n
시리즈 * n
시리즈 / n
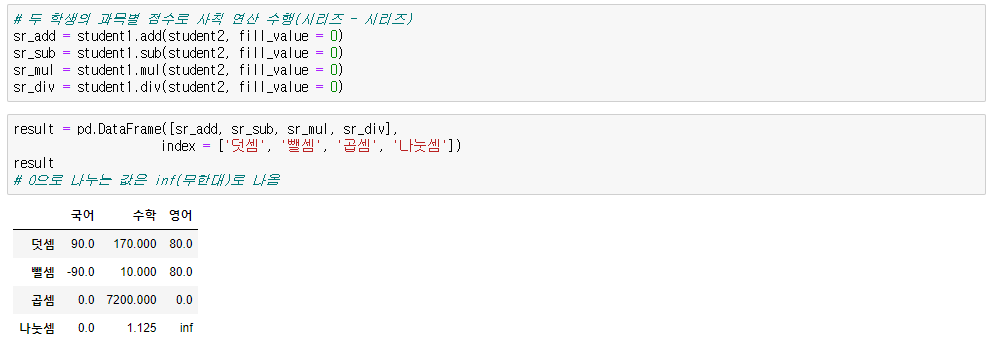
● Series to Series
시리즈 + 시리즈
시리즈 - 시리즈
시리즈 * 시리즈
시리즈 / 시리즈


→ 응용(Null 값일때 연산)


→ Null값을 0으로 대체 후 연산
● DataFrame to number
데이터프레임 + n
데이터프레임 - n
데이터프레임 * n
데이터프레임 / n


● DataFrame to DataFrame
데이터프레임 + 데이터프레임
데이터프레임 - 데이터프레임
데이터프레임 * 데이터프레임
데이터프레임 / 데이터프레임

'데이터 분석' 카테고리의 다른 글
| Matplotlib 그래프 & 그래프 세부설정 (라인그래프, 점그래프, 점&라인그래프, 면적그래프, 막대그래프), (스택 여부, 수평, 보조축) (0) | 2023.11.06 |
|---|---|
| Pandas Plot(판다스 그래프 그리기) (0) | 2023.10.31 |
| 데이터 분석 기초 (0) | 2023.10.31 |
| 판다스 데이터불러오기 (0) | 2023.10.31 |
| 판다스 기초 1 (0) | 2023.10.23 |



