▶ 데이터 불러오기
pd.read_csv(파일)

▶ 열 이름 지정
df.columns = [열1, 열2...]

▶ 데이터 확인
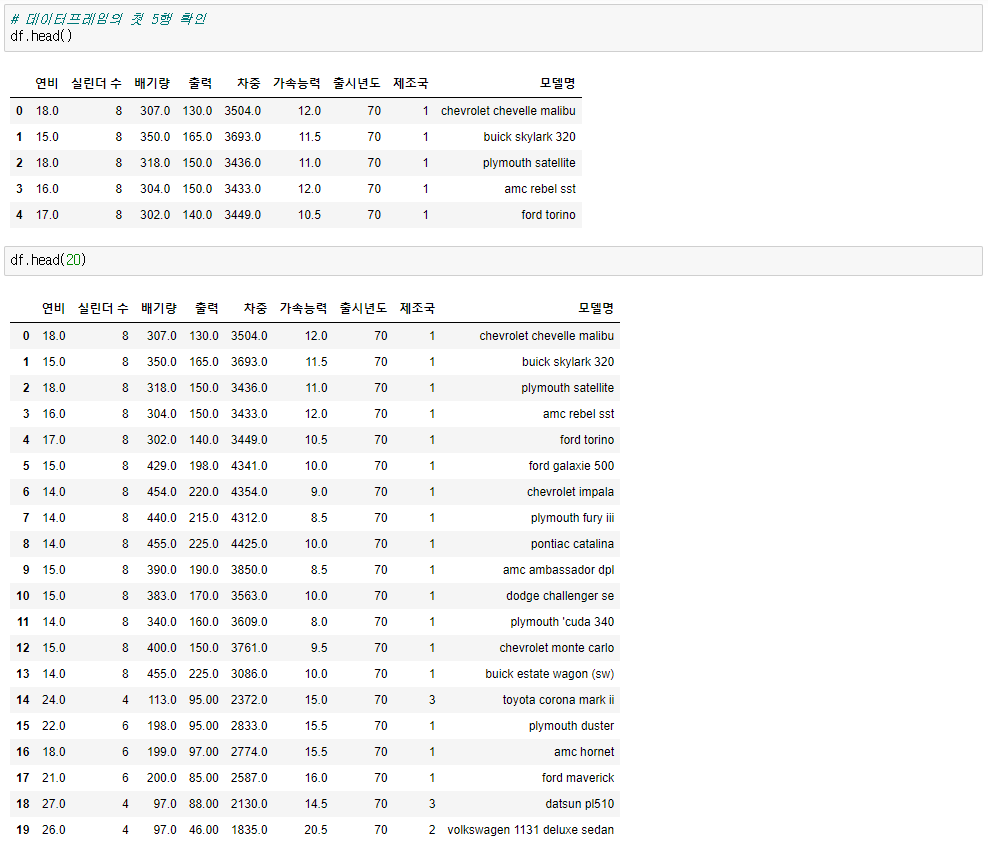
df.head()
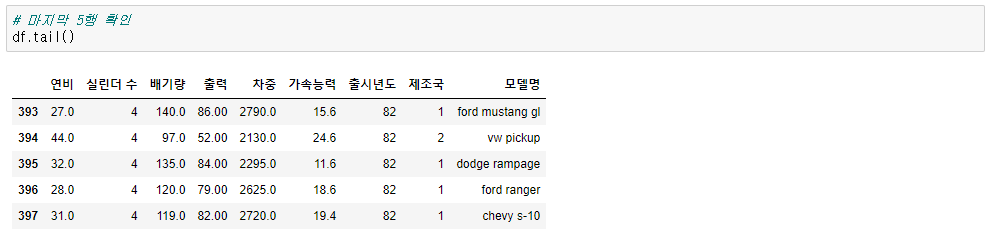
df.tail()
▶ 데이터 크기 확인
df.shape # 괄호 없음

▶ 데이터 프레임 요약
df.info()

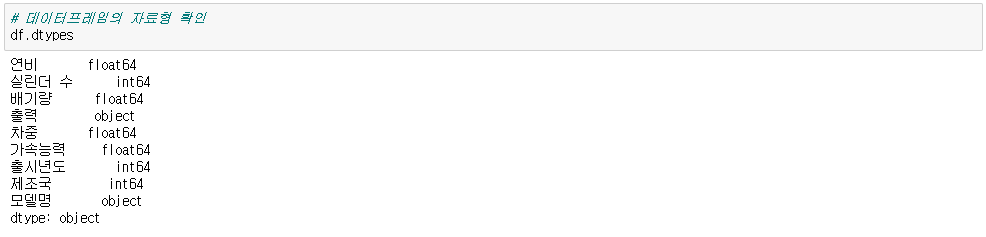
▶ 데이터 프레임의 자료형 확인
df.dtypes
▶ 기술통계 요약
df.describe() # 숫자형 데이터만
df.describe(include='object') # 문자형 데이터만 / object, 'O' 모두 가능
df.describe(include='all') # 모든 데이터

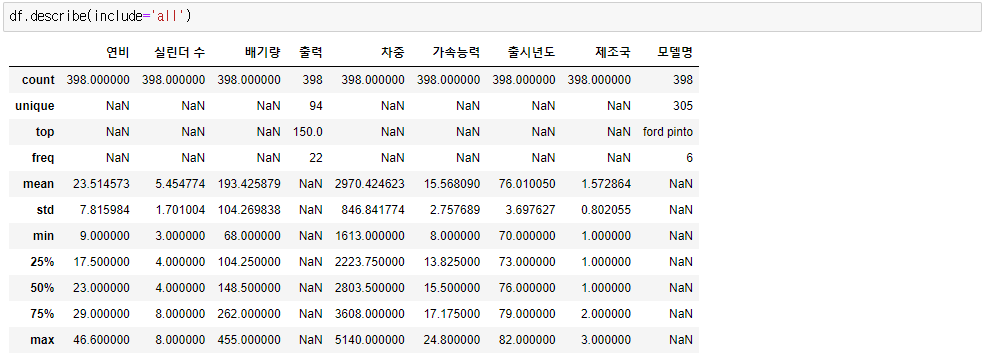
● count = 각 열의 null값을 제외한 값의 개수를 나타냄
● mean = 숫자형 데이터에 대한 평균값
● std = 숫자형 데이터에 대한 표준편차
● min = 숫자형 데이터의 최소값(문자열 데이터의 경우 가장 먼저 나타나는 값)
● 25% = 1사분위수
● 50% = 2사분위수(중위값, 중앙값)
● 75% = 3사분위수
● max = 숫자형 데이터의 최대값(문자열 데이터의 경우 가장 마지막에 나타나는 값)
● unique = 문자열 데이터의 고유값
● top = 문자열 데이터에서 가장 빈번하게 나타나는 값
● freq = top에서 나타난 값의 빈도수
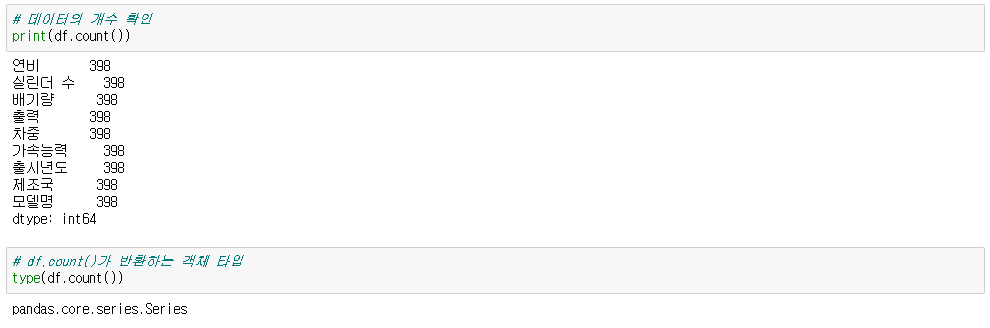
▶ 데이터의 개수 확인
df.count()
▶ 특정 컬럼이 가지고 있는 고유값, 고유값의 개수 확인
df[컬럼명].value_counts()

▶ 평균값 구하기
df.mean()

▶ 중앙값 구하기
df.median() # numeric_only : 숫자만

▶ 최대값 구하기
df.max()

▶ 최소값 구하기
df.min()

▶ 표준편차 구하기
df.std()

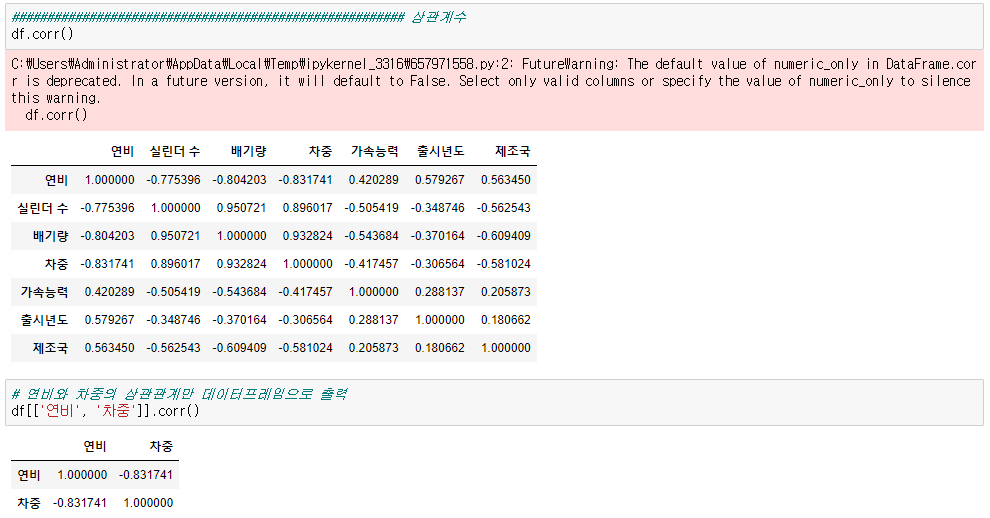
▶ 상관계수 구하기
df.corr()
'데이터 분석' 카테고리의 다른 글
| Matplotlib 그래프 & 그래프 세부설정 (라인그래프, 점그래프, 점&라인그래프, 면적그래프, 막대그래프), (스택 여부, 수평, 보조축) (0) | 2023.11.06 |
|---|---|
| Pandas Plot(판다스 그래프 그리기) (0) | 2023.10.31 |
| 판다스 데이터불러오기 (0) | 2023.10.31 |
| 판다스 기초 2 (0) | 2023.10.31 |
| 판다스 기초 1 (0) | 2023.10.23 |



