◆ 자동차 정보 데이터 분석
▶ 데이터 선택
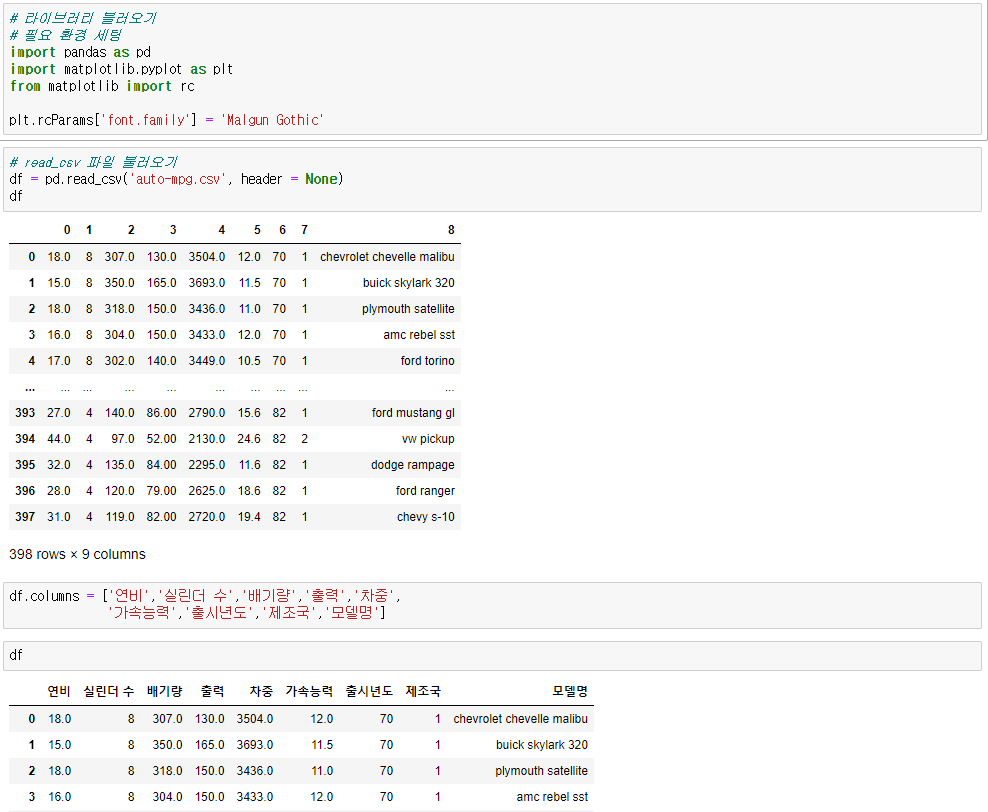
▶ 히스토그램
sr.plot(kind='hist', bins=10) # 시리즈형태 혹은 데이터프레임에서 한 컬럼 선택
# bins : 밀도 / 낮을수록 함축시킴
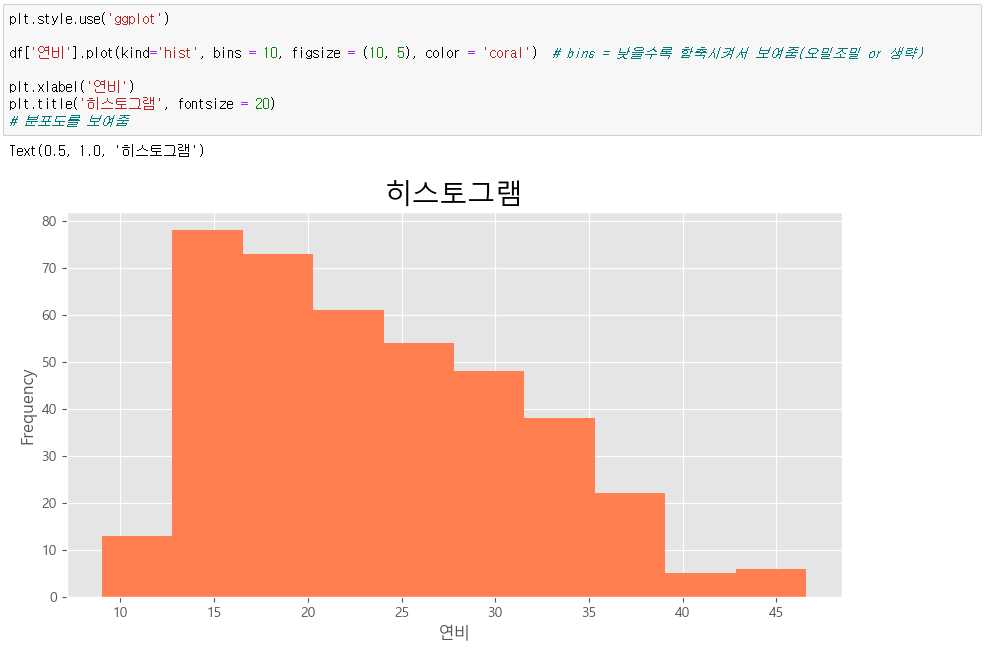
▶ Scatter plot
df.plot(kind='scatter', x='차중', y='연비', c= 'coral', s=30) # c : color / s : size(점 크기)
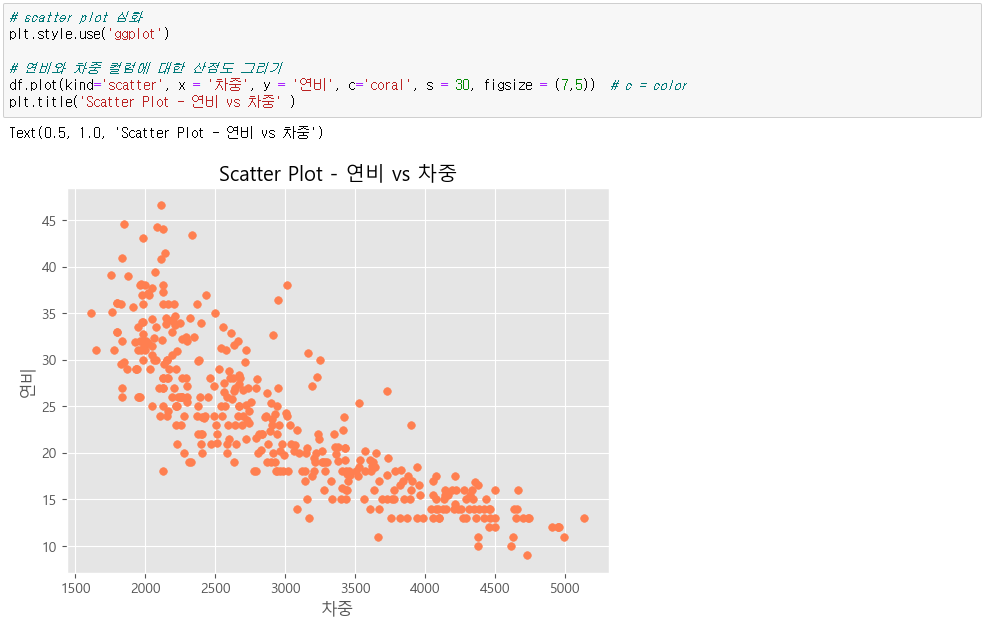
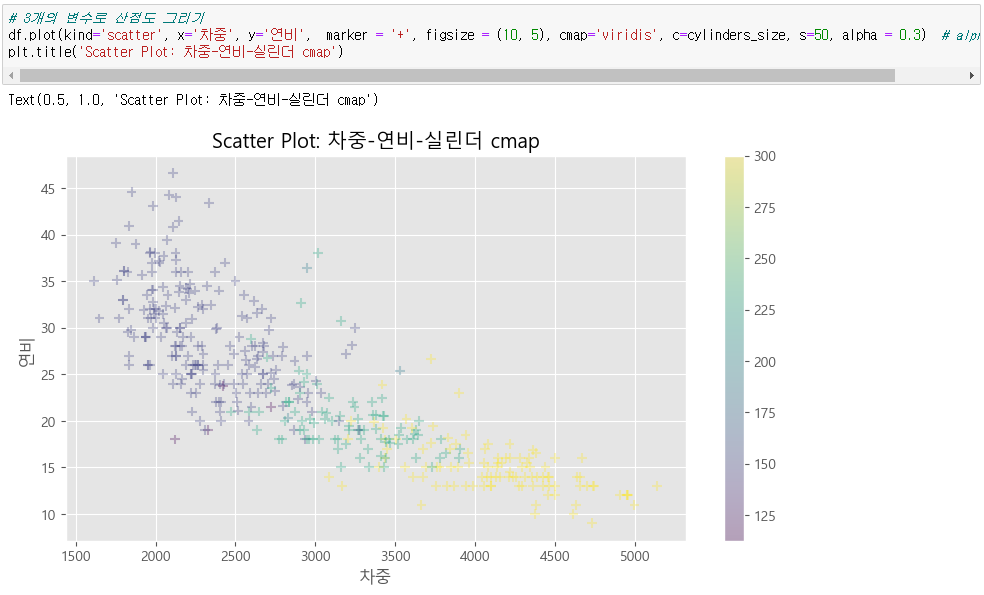
▶ 3개 변수로 산점도 그리기
● s = cylinders_size # 점 크기를 실린더 컬럼으로
● c = cylinders_size, cmap = 'viridis', alpha = 0.3 # 점 색깔을 실린더 컬럼으로 / cmap : 색깔 가이드 / alpha : 투명도

▶ 파이그래프
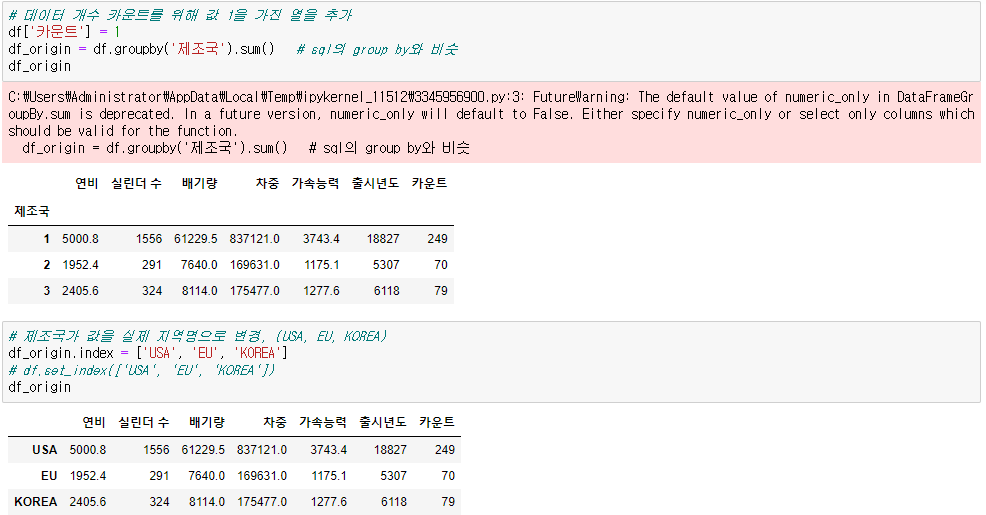
● 제조국별 카운트
df['카운트'] = 1 # 각 행에 1씩 부여
df.groupby(열 이름).sum() # 제조국별로 카운트 열 더하기
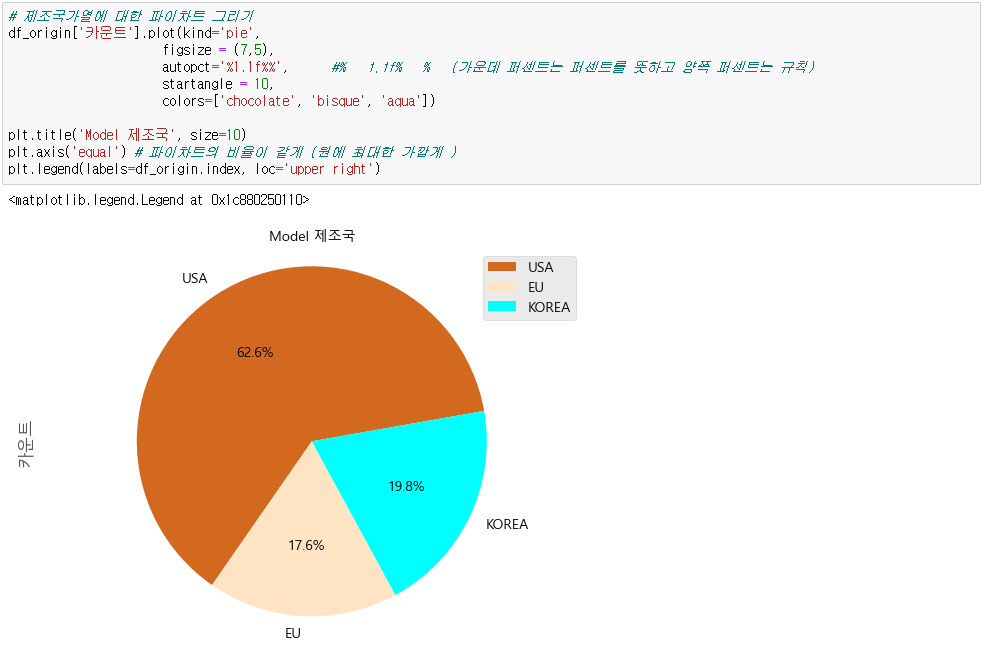
● 파이그래프 그리기
sr.plot(kind = 'pie', # 시리즈형태 혹은 데이터프레임에서 한 컬럼 선택 / 파이그래프 설정
autopct = '%1.1f%%', # 파이그래프 중간에 퍼센트 명시 / % 1.1f% % 양쪽 퍼센트는 규칙
startangle = 10 # 시작 각도
)
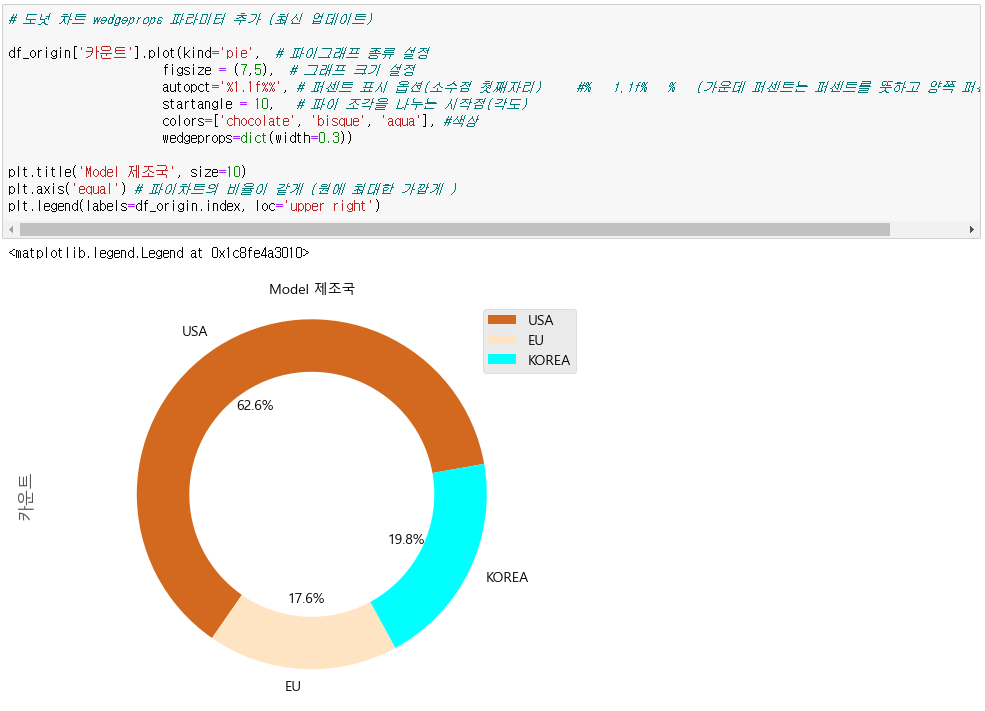
● 도넛그래프 그리기
sr.plot(kind = 'pie',
wedgeprops = dict(width = 0.3) # 도넛형으로 만들기 / width : 두께
)
▶ 박스플랏(boxplot)
axN.boxplot(x=[열1, 열2, 열3]
vert = Fasle) # 수직여부 (기본값 : True) fasle => 수평

◆ 와인데이터 분석
▶ 데이터 선택
▶ 산점도 & 회귀선
df.plot.scatter(x='밀도', y='알코올', # x, y축 설정
xlabel = '밀도', ylabel = '알코올', # x, y 이름 설정
xlim = (0.99, 1.01), ylim = (8, 15) # x, y 제한 설정
z = np.polyfit(df['밀도'], df['알코올'], 1) # 회귀값 계산
p = np.poly1d(z)
ax.plot(x축 데이터, p(x축 데이터), color = 'red') # 회귀선 그리기


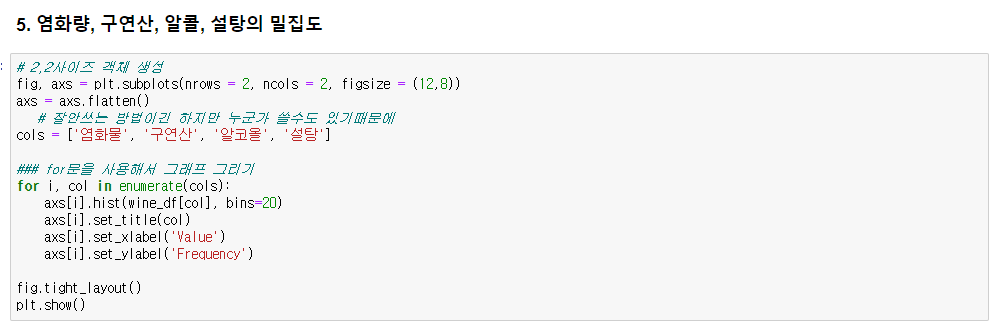
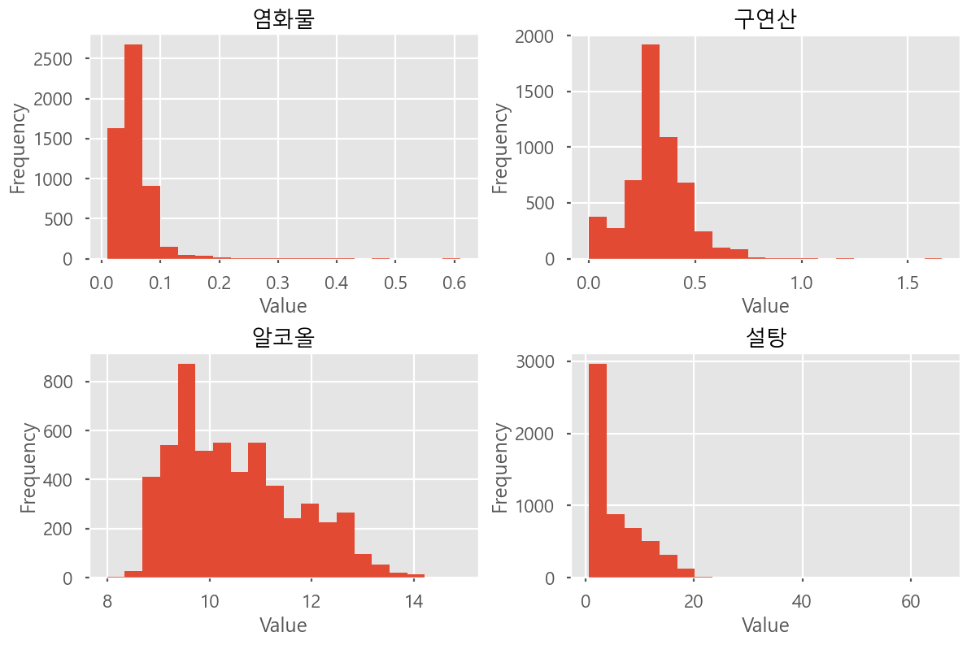
▶ 밀집도
fig, axs = plt.subplots(nrows = 2, ncols = 2, figsize = (12,8))
axs.flatten()
* enumerate() : 파라미터의 리스트의 인덱스 번호와 값 출력
axs[].hist() # 한 컬럼 히스토그램 그리기
'데이터 분석' 카테고리의 다른 글
| 판다스 데이터 전처리 (0) | 2023.11.07 |
|---|---|
| Seaborn (0) | 2023.11.07 |
| Matplotlib 그래프 & 그래프 세부설정 (라인그래프, 점그래프, 점&라인그래프, 면적그래프, 막대그래프), (스택 여부, 수평, 보조축) (0) | 2023.11.06 |
| Pandas Plot(판다스 그래프 그리기) (0) | 2023.10.31 |
| 데이터 분석 기초 (0) | 2023.10.31 |



