※ 라이브러리 임포트

◆ 결측값 처리
▶ 결측값 확인
● 결측값 개수 계산
df.value_counts(dropna=False) # dropna=False : NaN데이터를 제거하지 않고 count

● 결측값 찾기
df.isnull() # null -> True로
df.notnull() # null -> False로
df.isnull().value_counts() # True, False 개수 count
df.isnull().sum() # True를 1로 계산하여 총합 -> null값 개수 계산

▶ 결측값 처리
● 결측값 삭제
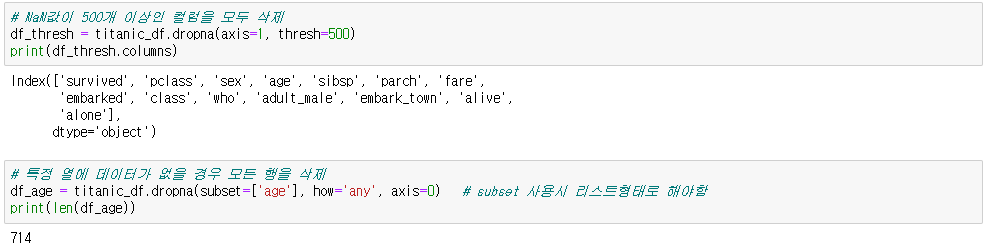
df.dropna(axis=1, # 결측값 있는 컬럼 삭제
thresh = 500) # 결측값이 500개 이상인 것 삭제
※ axis = 0 , 1 # 0: 행 , 1 : 열 / 기본값 0
df.dropna(subset=['age'], how='any', axis=0) # subset : 'age'컬럼에 적용 ( 리스트형태로 해야함 )
how : 방법 설정('any' : 결측치가 존재하면 제거, 'all' : 모두 결측치면 제거)
● 결측값 대체
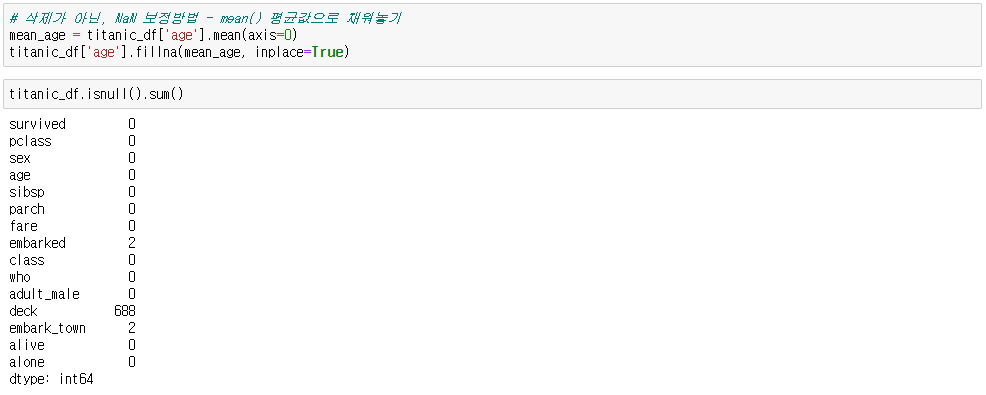
→ 평균값으로 대체
df.fillna(df.mean(axis=0), inplace = True) # df의 평균으로 결측값 채움 / inplace : 해당 df에 적용
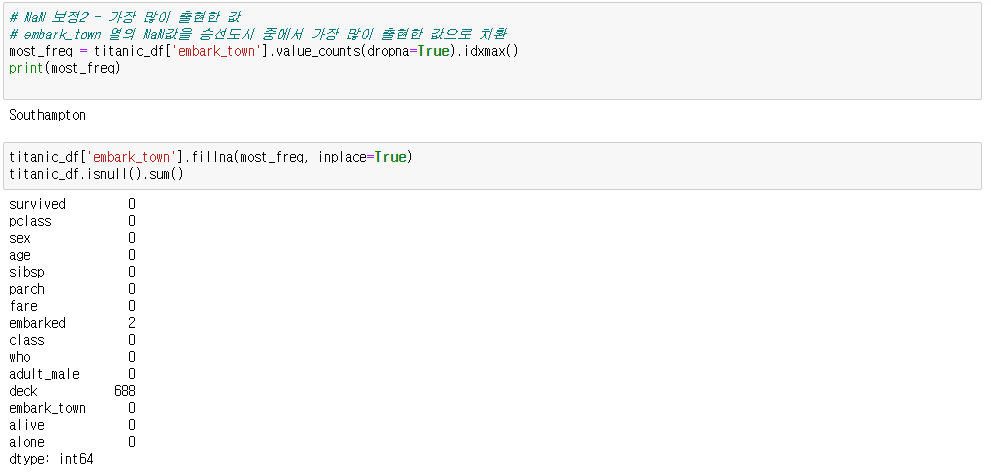
→ 최빈값으로 대체
df.fillna(df.value_counts(dropna=True).idxmax()) # df의 값들을 결측값을 제외하고 count한 후 가장 값이 큰 것으로
결측값 대체
→ 결측값의 앞의 값으로 대체
df.fillna(method='ffill') # method : 방법설정
ffill : 앞의 값으로 채우기(foward fill), bfill : 뒤의 값으로 채우기(backward fill)

◆ 중복값 처리
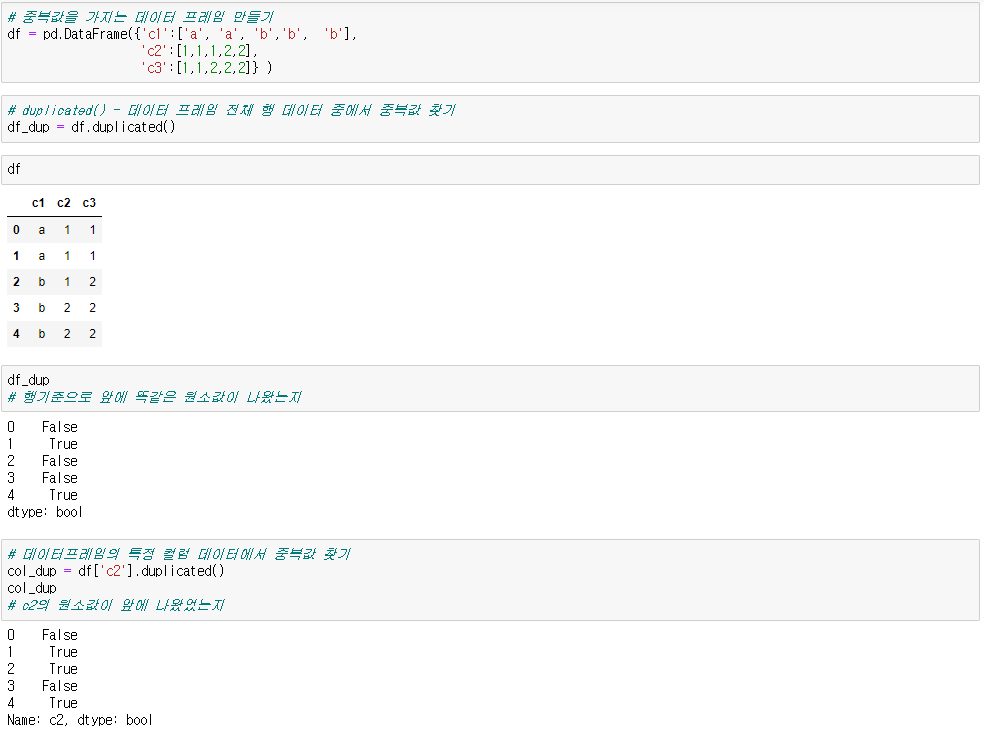
● 중복값 찾기
df.duplicated() # 중복값 찾기(행기준으로 앞에 똑같은 원소값이 나왔는지 boolean)
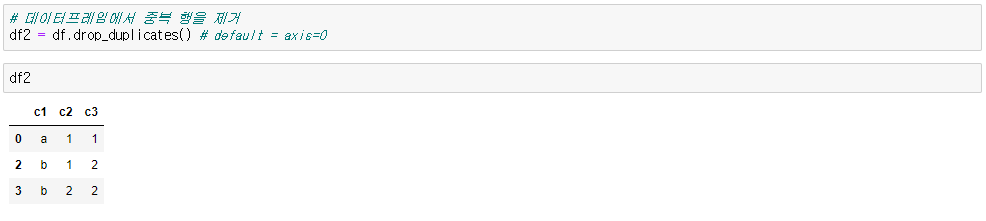
● 중복값 제거
df.drop_duplicates() # axis=0 , 1 / 기본값 : 0
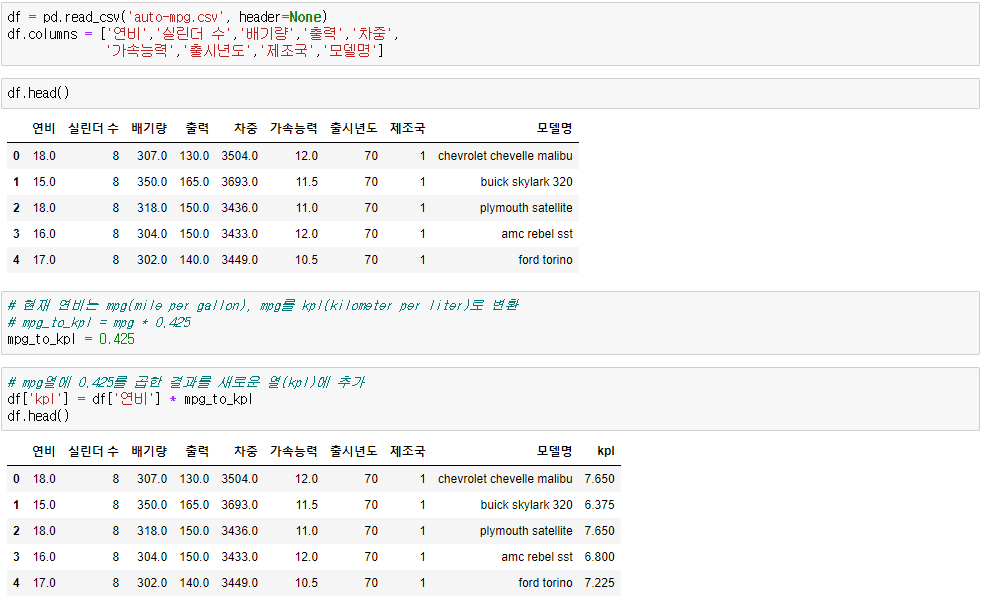
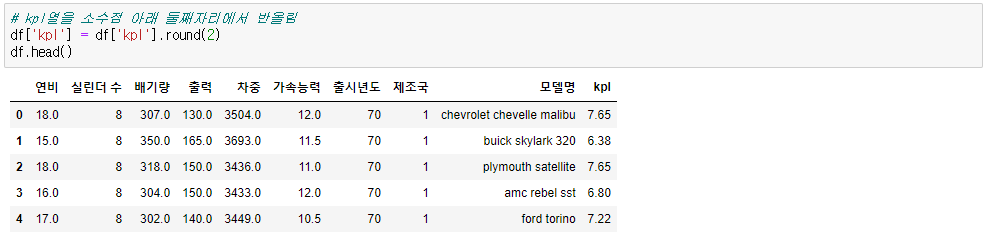
◆ 연산 전처리
◆ 데이터 프레임 자료형
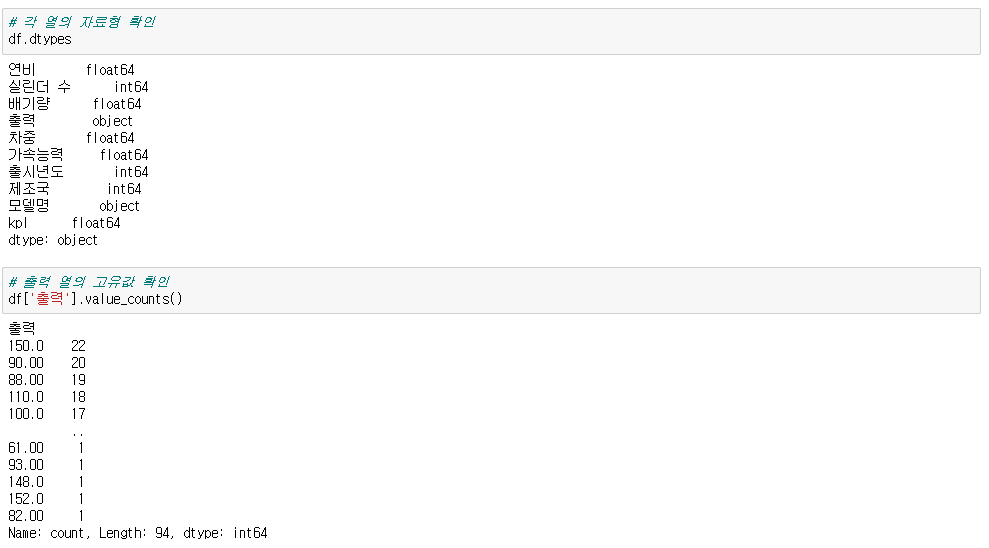
● 자료형 확인
df.dtypes
df.info()
● 자료형 변환
* df.unique() # 고유값 확인
* np.nan # numpy함수 nan(null) (결측값)
df.astype('float') # df의 자료형을 'float'형으로 변환


◆ Binning
count, bin_ = np.histogram(df, bins=3) # bin : 간격; 데이터를 간격으로 나눔
pd.cut(x=df, # 데이터 선택
bins = bin_, # 데이터 구간 리스트
labels = bin_names, # 경계값 이름
include_lowest = True) # 첫 경계값 포함 여부

'데이터 분석' 카테고리의 다른 글
| Regressor(KNeighborsRegressor) (0) | 2023.11.16 |
|---|---|
| KNeiborsClassifier (0) | 2023.11.16 |
| Seaborn (0) | 2023.11.07 |
| Matplotlib 분석(히스토그램, scatter plot, cmap, 파이그래프, boxplot) (0) | 2023.11.06 |
| Matplotlib 그래프 & 그래프 세부설정 (라인그래프, 점그래프, 점&라인그래프, 면적그래프, 막대그래프), (스택 여부, 수평, 보조축) (0) | 2023.11.06 |



