# pandas, matplot, seaborn 3가지 방법으로 plot을 그릴 수 있음
◆ Titanic 데이터셋 가져오기

◆ Titanic 데이터 변수 설명
- survived : 생존여부
- pclass : 탑승 등급
- sex : 성별
- age : 나이
- sibsp : 타이타닉호에 탑승한 형제 / 배우자의 수(int형)
- parch : 타이타닉호에 탑승한 부모 / 자녀의 수
- fare : 티켓가격
- embarked : 탑승 항구의 위치
- who : 남자, 여자 , 아이
- adult_male : 성인 남자인지 boolean(성인 남자면 True, 나머지는 False)
- deck : 선실 번호 첫 알파벳
- embar_twon : 탑승지의 이름
- alibe : 생존여부(str)
- alone : 혼자왔는지에 대한 boolean
◆ Titanic 데이터 형태

◆ 산점도 그리기(회귀선 유무)
# regplot의 기본값은 scatter + 자동으로 신뢰구간과 회귀선을 표시해줌
sns.regplot(x='age', y='fare', # x축, y축에 대입할 변수
data=titanic, # titanic 데이터를 지정
line_kws={'color' : 'red'}, # 회귀+신뢰구간 색상 지정
fit_reg=False) # 회귀선 미표시

※ 1차 방정식을 이용한 회귀선은 데이터 포인트들 간의 관계를 나타내는 직선이며, 이 직선은 데이터의 중심을 지나면서 데이터 포인트들과의 거리(오차)를 최소화하는 방향으로 그려짐
※ 회귀선은 주어진 독립변수(x축)에 대한 종속변수(y축)의 예측값을 나타내는 지표로 사용할 수 있음
※ 신뢰구간은 회귀선의 신뢰도를 나타내는 영역으로 데이터의 분산, 표본 크기에 따라 너비가 변경됨
※ 데이터 포인트가 회귀선 주위로 밀집되어 있다면 신뢰구간이 좁아지며, 신뢰구간의 너비가 넓다는 것은 회귀선의 위치에 대한 불확실성이 높다는 것
◆ Displot, Kdeplot, Histplot
sns.distplot(sr(df[])) # 시리즈 또는 df 한 컬럼으로 displot그리기
sns.kdeplot(x='fare', data=titanic) # titanic data에서 x축을 'fare'컬럼으로 kdeplot그리기
sns.histplot(x='fare', data=titanic) # titanic data에서 x축을 'fare'컬럼으로 histplot그리기


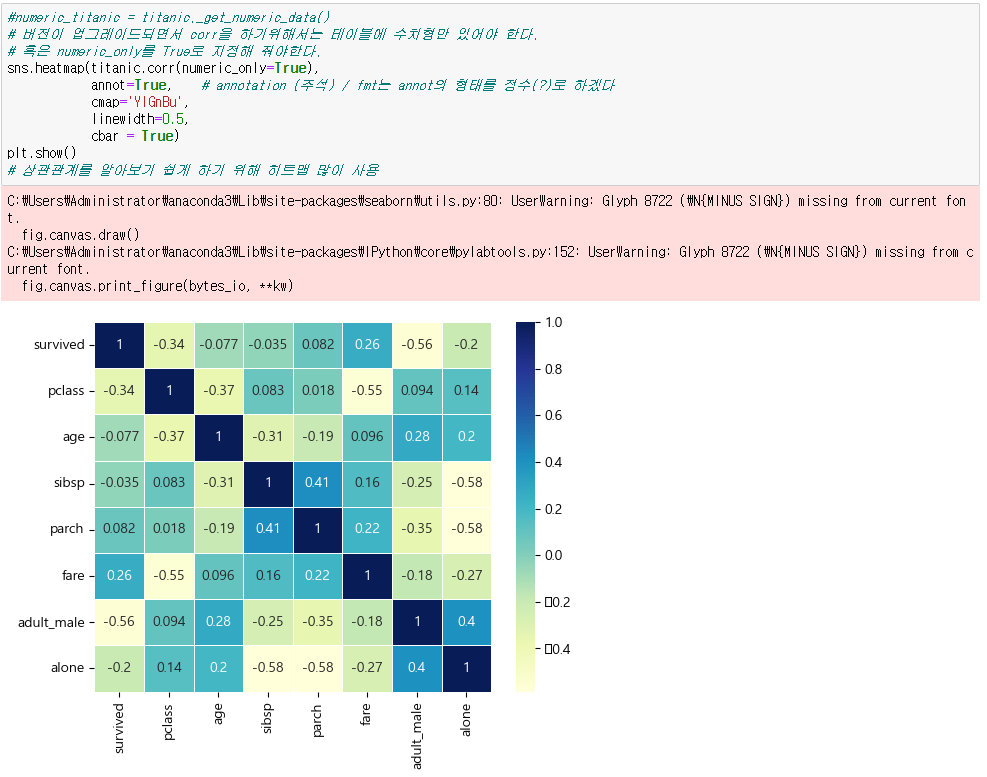
◆ 히트맵 그리기
● 피벗테이블
df.pivot_table(index=['sex'], columns=['class'], aggfunc='size') # 인덱스를 'sex'컬럼으로, 컬럼을 'class' 컬럼으로
aggfunc : 집계함수

※ aggfunc 함수
합계 : np.sum() / 평균 : np.mean() / 표준편차 : 'std' / count : 'count', 'size' / distinct count : 'nunique'
/ 최대값 : np.max, 'max' / 최소값 : np.min, 'min'
● 히트맵 그리기
sns.heatmap(table, # 테이블을 table로 설정
annot=True, # 주석 설정
fmt = 'd', # 주석형태를 'd'(정수)타입으로 설정
cmap='YlGnBu', # cmap을 YlGnBu로 설정
linewidth=0.5, # 선 굵기
cbar = True # color bar 설정

sns.heatmap(titanic.corr(numeric_only=True)) # numeric_only : 수치형 데이터만 선택
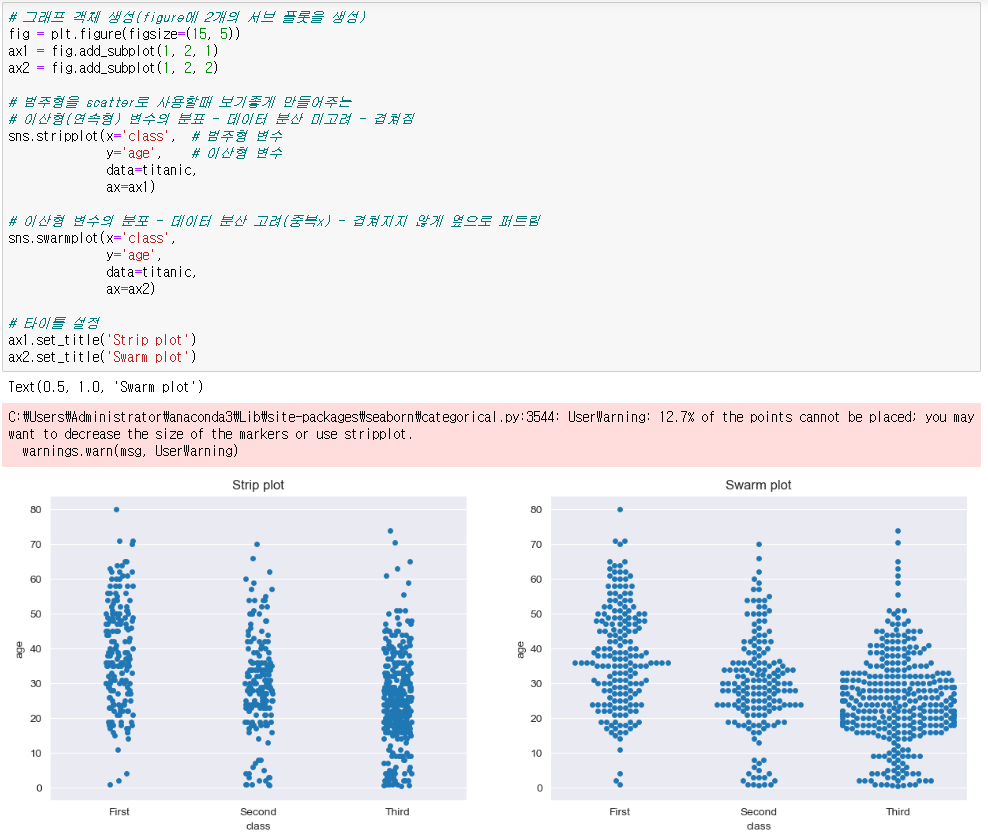
◆ Strip plot, Swarm plot(범주형 데이터로 scatter를 만들려할때)
sns.stropplot(x='class', # x축 데이터를 'class' 컬럼으로 설정 / 범주형 데이터
y='age' # y축 데이터를 'age' 컬럼으로 설정 / 이산형 데이터
data = titanic, # data를 titanic으로 설정
ax=ax1) # 화면 설정
sns.swarmplot(x='class', # 범주형 데이터
y='age' # 이산형 데이터
data = titanic,
ax=ax1)
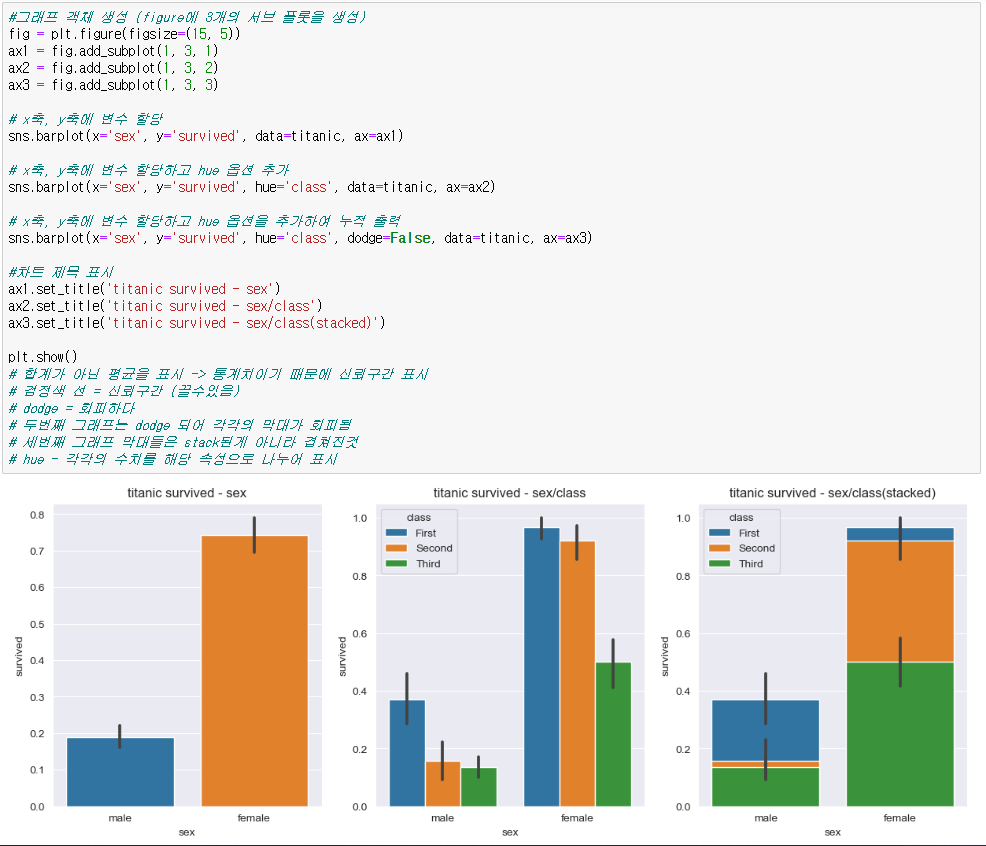
◆ Bar plot(신뢰구간 표시)
sns.barplot(x='sex', y='survived', # x, y축 데이터 컬럼 선택
hue='class', # 세부 옵션 설정 / 'class' 컬럼으로 나누어 표시
dodge=False, # dodge=False : 세부 설정 막대들을 겹쳐보이게(회피하지 않음)
data=titanic, ax=ax1) # data를 titanic으로 화면을 ax1로
◆ 빈도 그래프(Count plot)
sns.countplot(x='class', # x축 데이터를 'class'컬럼으로 설정
hue = 'who', # 세부옵션을 'who'컬럼으로 설정
palette = 'Set1', # 색깔 세트를 'Set1'으로 설정
dodge = False, # 회피하지 않음
data = titanic, ax=ax1) # titanic을 데이터로 선택, 화면을 ax1으로 설정

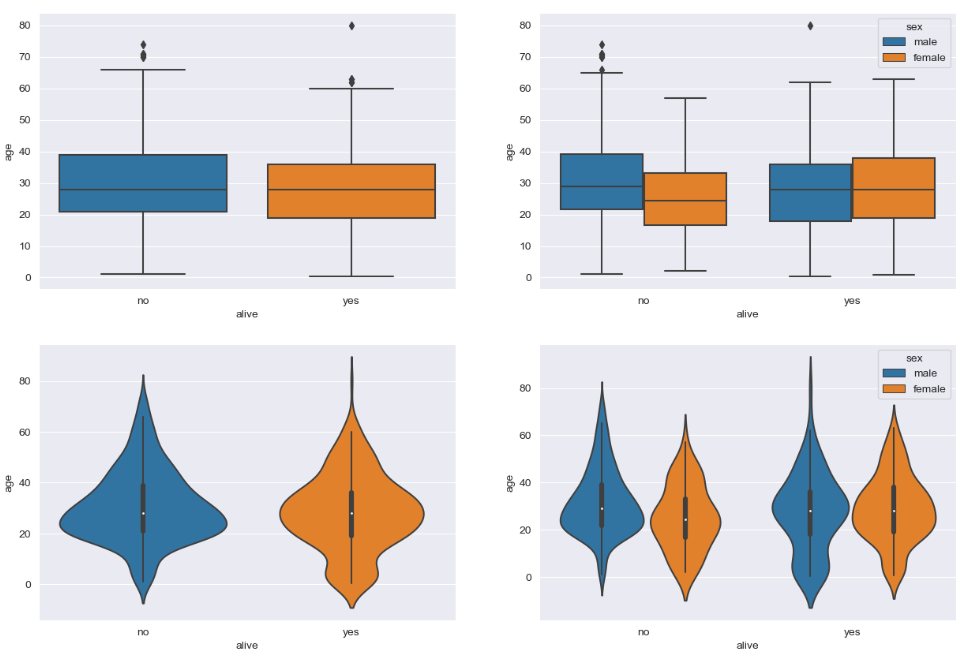
◆ Box plot & Violin plot
sns.boxplot(x='alive', y='age', # x축, y축 데이터를 각각 'alive', 'age'컬럼으로 설정
hue = 'sex', data=titanic, ax=ax1) # 세부옵션을 'sex' 컬럼으로 설정
sns.violinplot(x='alive', y='age', # x축, y축 데이터를 각각 'alive', 'age'컬럼으로 설정
hue = 'sex', data=titanic, ax=ax1) # 세부옵션을 'sex' 컬럼으로 설정

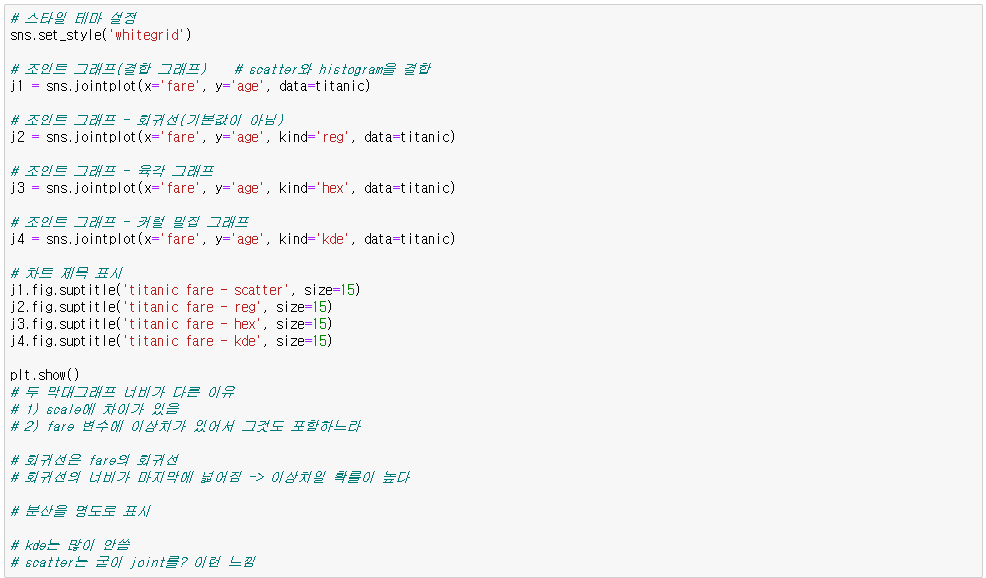
◆ Joint plot
sns.jointplot(x='fare', y='age', kind='reg', data=titanic) # x축, y축 데이터를 각각 'fare', 'age' 컬럼으로 설정
* kind = 'reg', 'hex', 'kde' # 'reg' : 회귀선 추가 / 'hex' : 육각형 모양으로 설정 / 'kde' : 등고선 모양으로 설정




◆ FacetGrid ( 조건에 따라 그리드 분할)
sns.FacetGrid(data=titanic, col='who', row = 'survived') # data를 titanic으로 설정
열을 'who'컬럼에 따라 분할 / 행을 'survived'컬럼에 따라 분할
g.map(plt.hist, 'age') # 'age' 컬럼 데이터로 histogram 그리기

◆ Pair plot( 한번에 histogram, scatter 그리기)
sns.pairplot(titanic[['age', 'pclass', 'fare']]) # titanic데이터의 'age', 'pclass', 'fare'컬럼으로 그리기
# 사용을 권장하진 않음


'데이터 분석' 카테고리의 다른 글
| KNeiborsClassifier (0) | 2023.11.16 |
|---|---|
| 판다스 데이터 전처리 (0) | 2023.11.07 |
| Matplotlib 분석(히스토그램, scatter plot, cmap, 파이그래프, boxplot) (0) | 2023.11.06 |
| Matplotlib 그래프 & 그래프 세부설정 (라인그래프, 점그래프, 점&라인그래프, 면적그래프, 막대그래프), (스택 여부, 수평, 보조축) (0) | 2023.11.06 |
| Pandas Plot(판다스 그래프 그리기) (0) | 2023.10.31 |



