◆ 데이터 준비

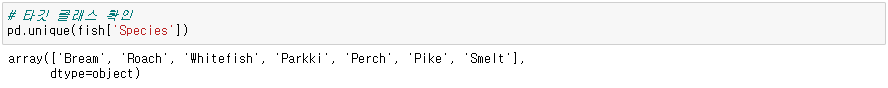

● 테스트 셋 나누기 & 정규화

◆ k-최근접 이웃 분류기의 확률 예측

◆ 로지스틱 회귀(Logistic regression)
- 분류의 확률을 구할때 자주 사용
- y=ax+b 선형회귀식을 이용해서 확률을 구함
- 문제는 음수가 나올 수 있음
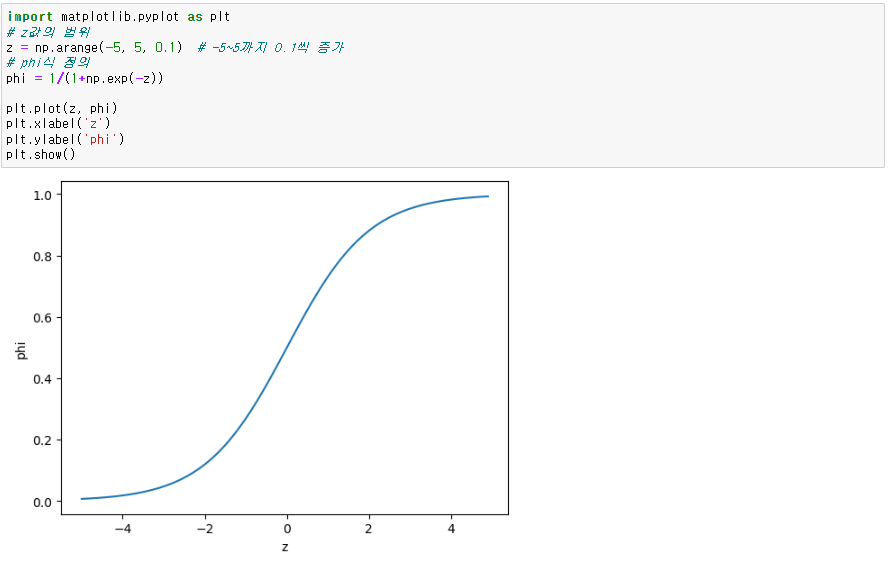
- 시그모이드 함수로 이를 0~1값으로 변경
● 시그모이드 함수
- 회귀모델을 통해 나오는 값을 확률로 만들어 줌
▶ 로지스틱 회귀 모델 & 예측(이진분류)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit()
lr.predict()
lr.predict_proba()

● 타깃 클래스, 기울기, 절편 확인
lr.classes_
lr.coef_
lr.intercept_

● z값(ax+b) 출력 - 선형식으로 행마다 계산한 결과
lr.decision_function(데이터)

● 시그모이드 함수에 z값 넣기(확률)(비교용)
- 분류 클래스 0과 1중 1의 확률을 출력
from scipy.special import expit
expit(z값)

▶ 로지스틱 회귀 모델 & 예측(다중분류)
lr = LogisticRegression(C=20, max_iter=1000) # C : 규제 정도 (릿지와 라쏘에서의 alpha), 클수록 규제 감소

# 이진분류 - 로지스틱회귀 -> 시그모이드
# 다중분류 - 로지스틱회귀 -> softmax
# 로지스틱회귀를 사용하면 이진분류랑 다중분류를 자동으로 인식하여 적용됨
● z값 출력 및 소프트 맥스에 z값 적용(확률)(비교용)
from scipy.special import softmax
softmax(z값, axis=1)

'데이터 분석' 카테고리의 다른 글
| Decision_Tree(의사결정나무) (0) | 2023.12.12 |
|---|---|
| Stochastic Gradient Descent(SGD, 확률적 경사 하강법) (0) | 2023.12.12 |
| Feature_engineering (0) | 2023.12.12 |
| LinearRegression (0) | 2023.11.17 |
| Regressor(KNeighborsRegressor) (0) | 2023.11.16 |



