◆ 데이터 준비


● 로지스틱 회귀
◆ 결정트리
- XAI(AI의 의사결정을 사람이 이해하기 쉽게 설명하는 것)에서 많이 사용됨
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit()
dt.score()
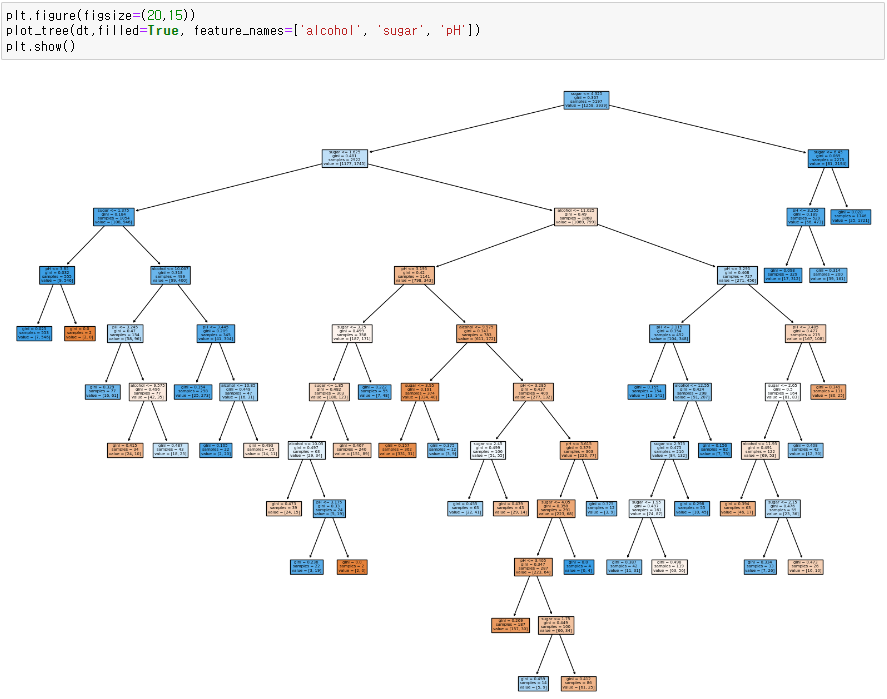
● 결정트리 그리기
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plot_tree(dt)
plt.show()
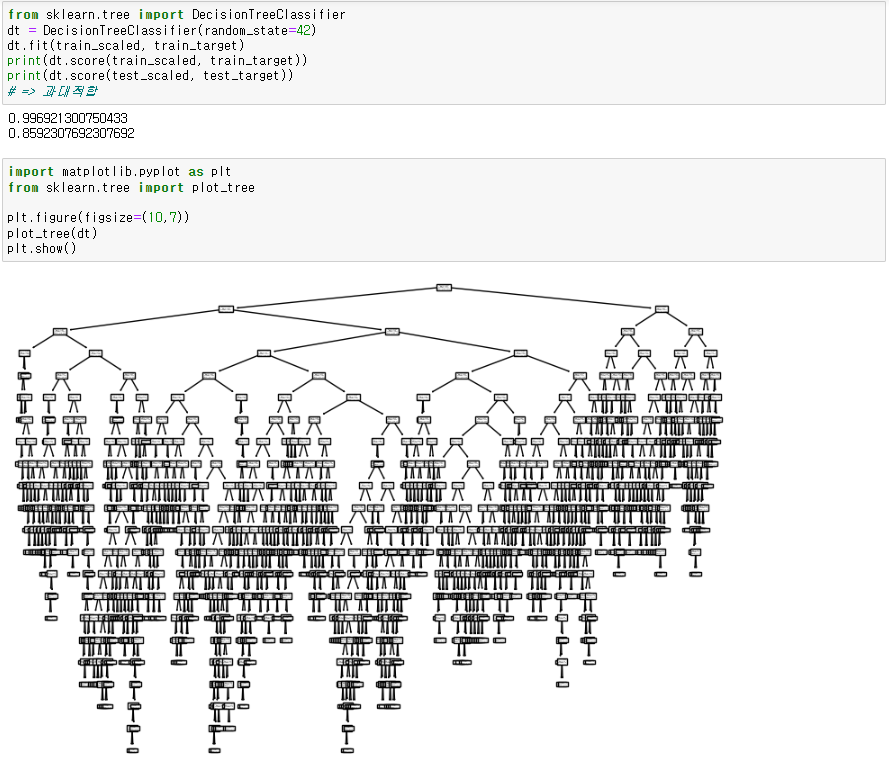
● 결정트리 구성
노드 : 나누는 질문을 하는 상자
루트노드 : 맨위 노드
리프노드 : 맨마지막 노드
gini : 편향, 불순도 - 0과 1의 비율
- 0.5에 가까울수록 잘 나눠지지 않은 것 / 0이나 1에 가까울수록 전 질문으로 잘 나뉘어진 것
value = [0번클래스의 수, 1번클래스의 수]
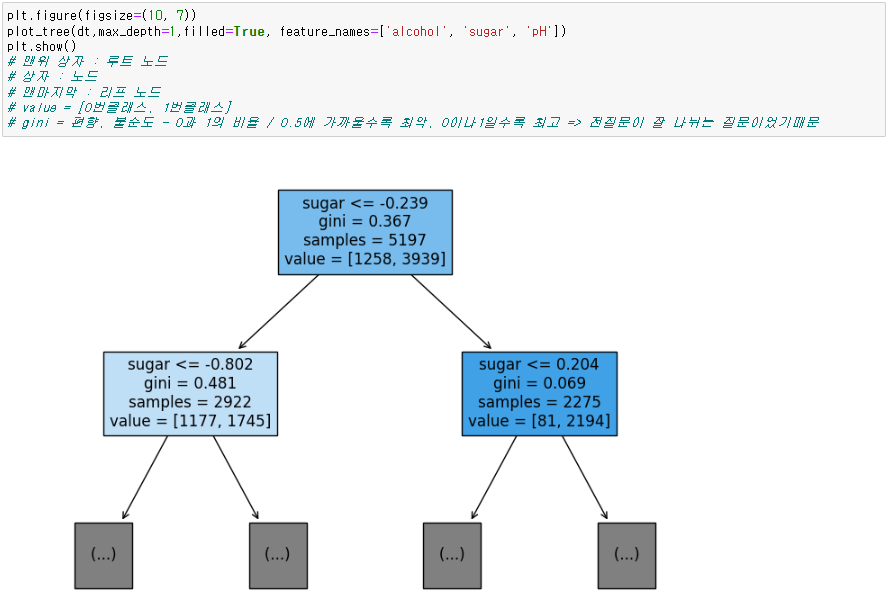
※ 가지를 치는 기준
- 상위노드의 불순도와 하위노드의 불순도를 보고 가지를 침
-> 가지를 칠 필요가 없다 생각되면 멈춤
- 식 :
상위노드의 불순도 - (왼쪽노드샘플 수 / 상위노드 샘플 수) x 왼쪽 노드 불순도
- (오른쪽 노드샘플 수 / 상위노드 샘플 수) x 오른쪽 노드 불순도
- 이렇게 상위노드와 하위노드의 불순도 차이를 정보이득이라고 한다.
- 결정트리는 이 정보이득이 최대가 되도록 데이터를 나눔
▶ 가지치기
● 최대 깊이로 제한
dt = DecisionTreeClassifier(max_depth= ) # depth 설정
# 색변화 => 클래스의 수가 역전될때
# 분류 최적루트는 진한 색 루트(여기서는 1번클래스)와 색이 바뀌는 루트(여기서는 0번클래스)를 따라가면 됨

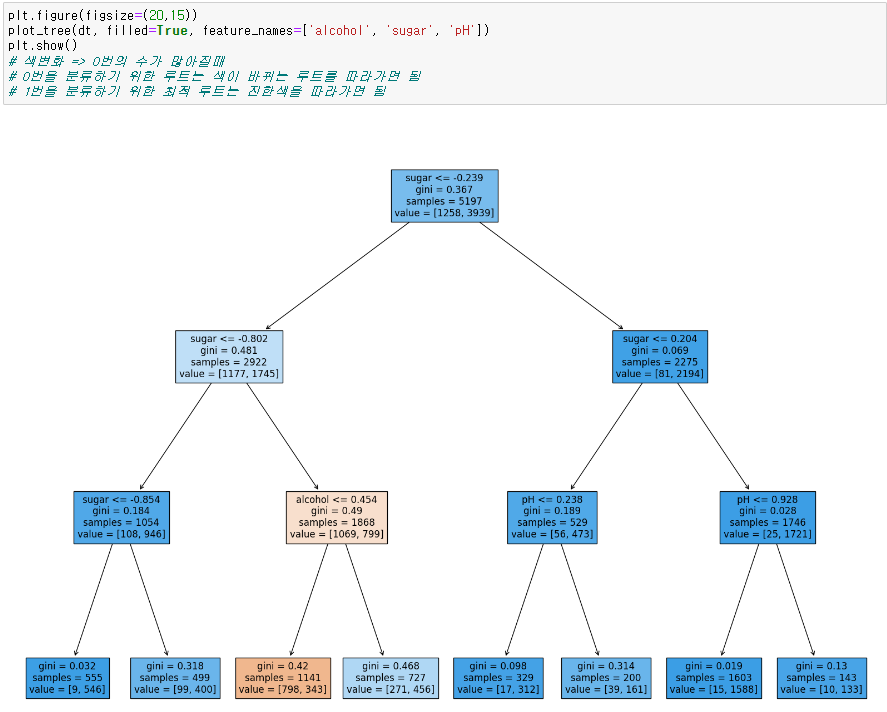
※ 조건식으로 나누기 때문에 스케일링을 안쓰고 해도 동일함

※ 특성에 따른 중요도 확인
dt.feature_importances_

● 정보이득에 따른 제한
dt = DecisionTreeClassifier(min_impurity_decrease= ) # 해당 값보다 정보이득이 크면 가지를 치고 작으면 종료

'데이터 분석' 카테고리의 다른 글
| Ensemble(앙상블)(RandomForest, GB, HGB, XGB, LGBM) (0) | 2023.12.13 |
|---|---|
| Cross_Validation(교차검증) & GridSearchCV (0) | 2023.12.13 |
| Stochastic Gradient Descent(SGD, 확률적 경사 하강법) (0) | 2023.12.12 |
| Logistic_regression (0) | 2023.12.12 |
| Feature_engineering (0) | 2023.12.12 |



