◆ 확률적 경사 하강법
- 머신러닝 모델이 아님
- 알고리즘을 학습할때 사용
- 머신러닝 알고리즘에 대한 최적의 매개변수 구성을 찾는 방법
- 손실함수 - 머신러닝 평가지표
- 어떻게 하면 손실이 적어질지 학습 -> 손실을 줄이기 위해 하나하나씩 학습
- 데이터가 끝나면 다시 데이터를 랜덤으로 뽑음(확률적) -> 한 사이클 : 1 epoch
<-> 미니배치하강법 - 조금도 많이씩 학습
<-> 배치하강법 - 모두 가져와 학습
● 이진 크로스 엔트로피 손실함수 -> 분류모델의 손실값을 정의하는 함수
- 실제 샘플이 양성클래스면 1에 가까울수록 좋은 예측이므로 예측값에 -1을 곱해 음수를 취한다.
1에 가까울수록 작은 손실을 만들어 줄 수 있다.
- 실제 샘플이 음성클래스면 0에 가까울수록 좋은 예측이므로 1에서 예측값을 뺀 후 -1을 곱해 음수를 취한다.
| 예측 | 1 | 0 | 0 | 1 |
| 확률 | 0.9 | 0.3 | 0.1 | 0.7 |
| X | ||||
| 실제 | 1 | 1 | 0 | 0 |
| 변환 | 0.9 * -1 | 0.3 * -1 | (1-0.1) * -1 | (1-0.7) * -1 |
| 손실 | -0.9 | -0.3 | -0.9 | -0.3 |
(맞힌 값) < (틀린 값) (맞힌 값) < (틀린 값) # 보통 -log를 취해서 손실로 사용
◆ 데이터 준비
◆ 확률적 경사 하강법 모델 학습
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter= ) # loss='log_loss' : 손실함수 / max_iter : epoch(반복횟수)
sc.fit()
sc.score()
sc.partial_fit() # 에폭 1회 늘리기 - epoch을 다시 설정할필요 없이 1회씩 늘릴 수 있음

● 에포크와 과대/과소적합
- 에포크가 낮으면 과소적합, 높으면 과대적합이 일어날 가능성이 높음
for _ in range(0,300): # 대입하는 변수없이 횟수로 그냥 반복
sc.partial_fit()
# 0~50 : 과소적합, 250~300 : 과대적합
# 과대적합이 일어나기 직전까지 최대한 학습하는 것이 좋다
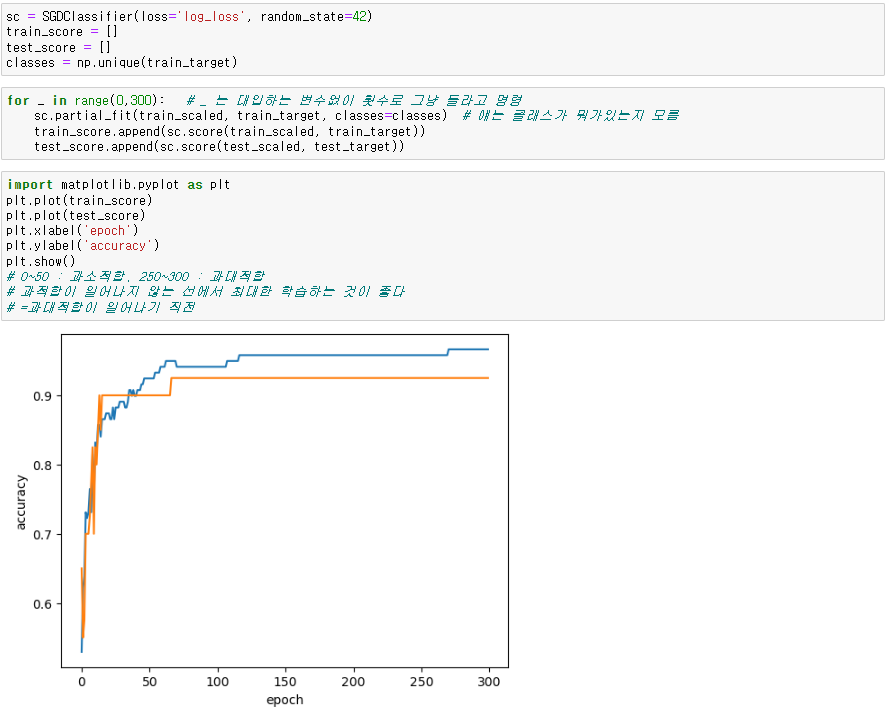
※ tol=None - 중지하지 않고 사용자가 설정한 값 모두 실행
# 보통 점수에 변화가 없으면 과대적합이 될수있어 중지됨
sc = SGDClassifier(loss='log_loss', max_iter=, tol=None)

'데이터 분석' 카테고리의 다른 글
| Cross_Validation(교차검증) & GridSearchCV (0) | 2023.12.13 |
|---|---|
| Decision_Tree(의사결정나무) (0) | 2023.12.12 |
| Logistic_regression (0) | 2023.12.12 |
| Feature_engineering (0) | 2023.12.12 |
| LinearRegression (0) | 2023.11.17 |



