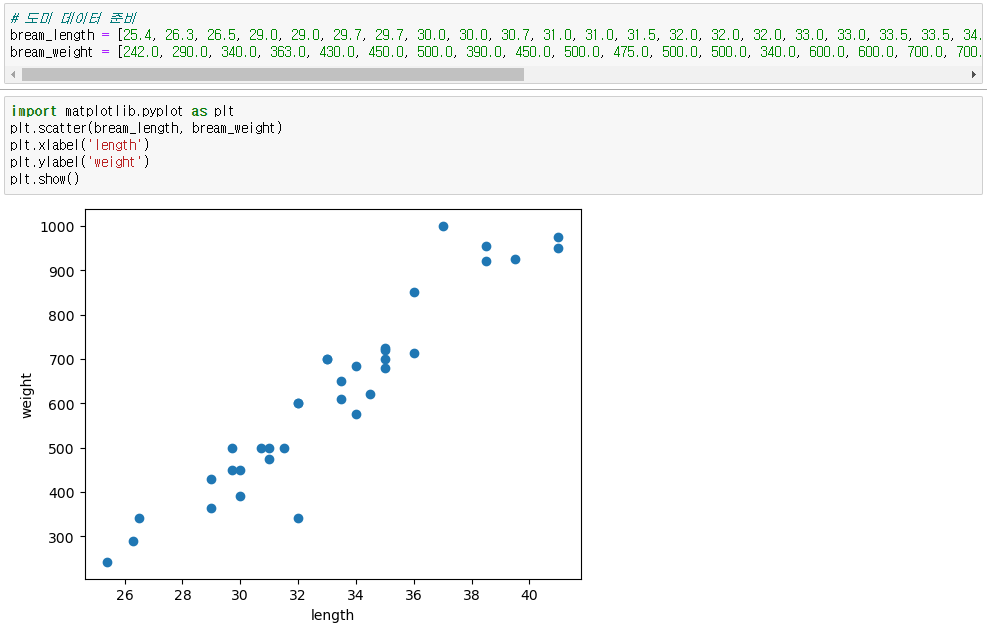
◆ 데이터 준비
1. 도미 데이터
2. 빙어데이터
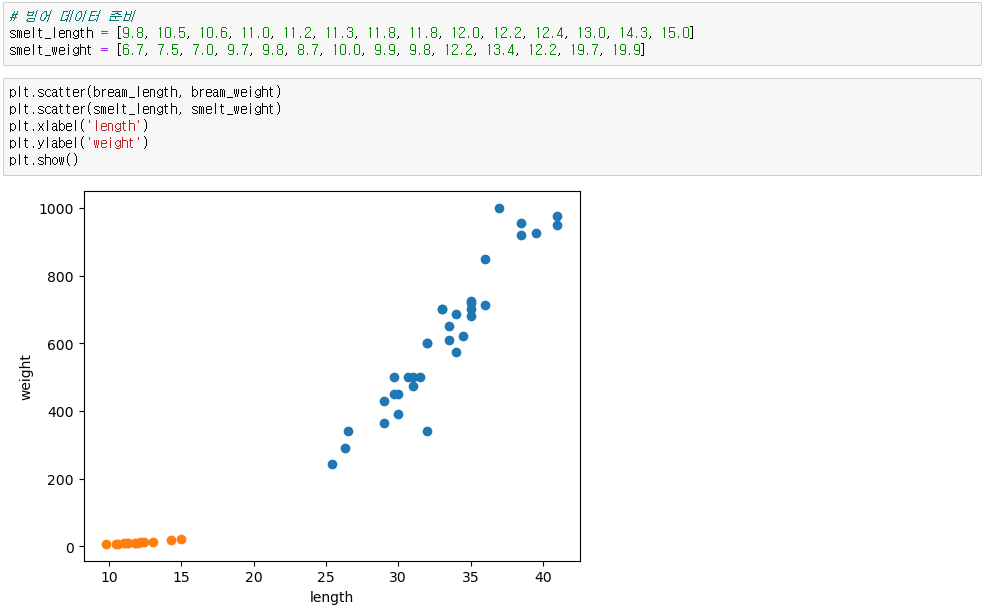
◆ 독립변수, 종속변수 만들기


◆ K-NeighborsClassifier
● 임포트 & 객체 생성
from sklearn.neighbors import KNeighorsClassifier
kn = KNeighborsClassifier()
● 모델 훈련
kn.fit(독립변수, 종속변수)

● 정확도 테스트
kn.score(독립변수, 종속변수)

※ 그래프로 표시
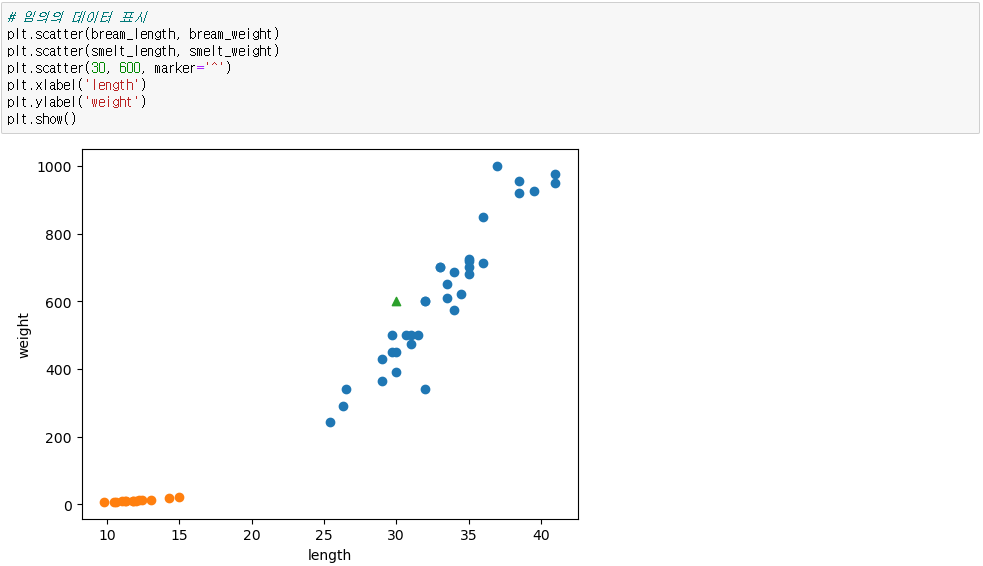
● 예측
kn.predict([[독립변수, 종속변수]])) # 2차원 데이터

● 훈련된 데이터 확인
kn._fit_X
kn._y


● 하이퍼파라미터 튜닝
▶ 파라미터
n_neighbors=

◆ 검증데이터 할당하기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(독립변수, 종속변수,
random_state=42, # 랜덤계수 설정
stratify=fish_target) # fish_target의 비율에 따라 나누기

◆ K-NeighborsClassifier의 주의점
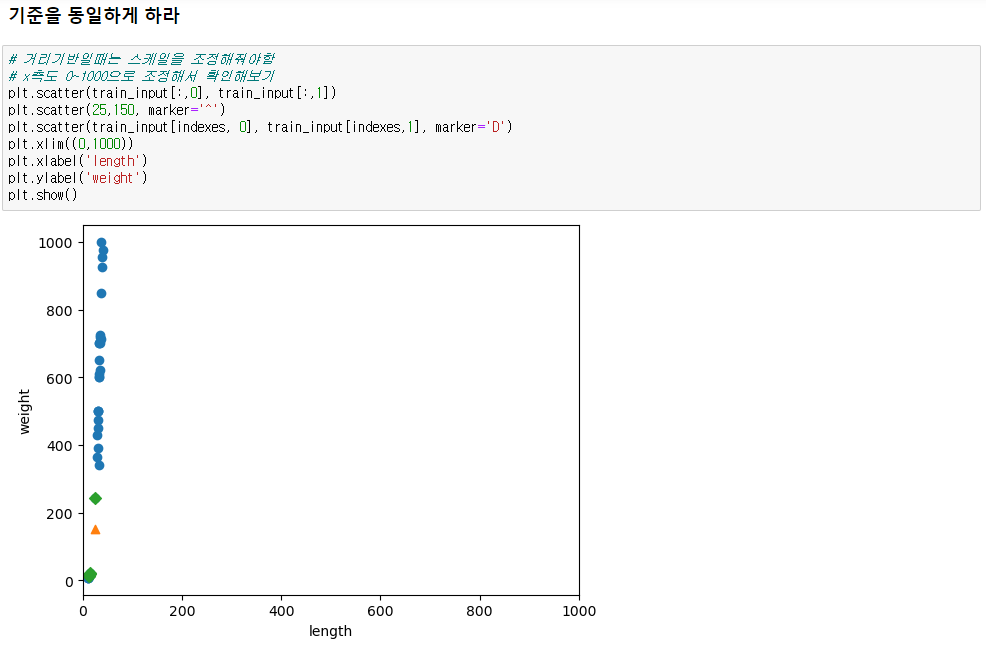
▶ 스케일링
● 문제 감지 - 그래프상으로는 도미에 가깝지만 결과는 빙어(0)으로 나옴

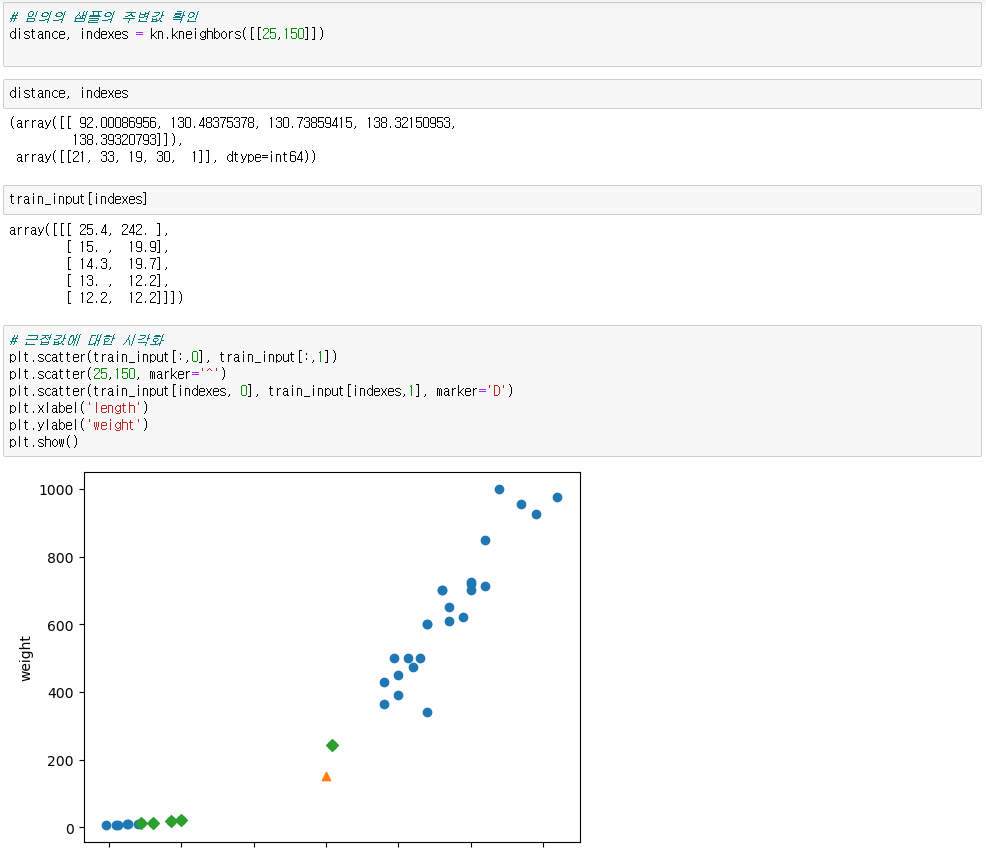
● 해결방안 : 스케일링
* 문제이유 : 변수들의 수치가 달라 수치 거리상으로 빙어에 가깝게 나옴
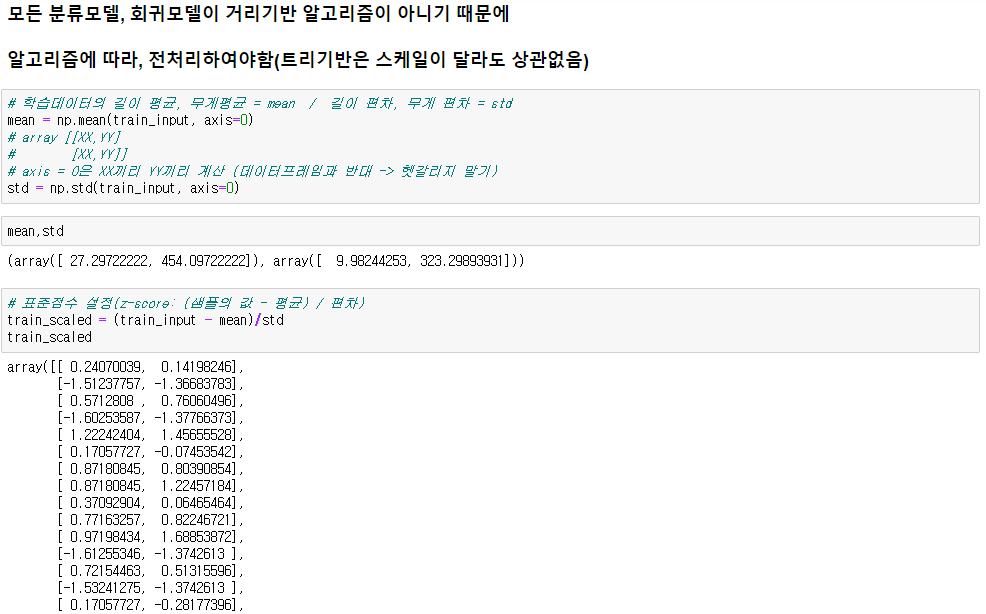
● 표준화(Z-score)
(샘플의 값 - 평균)/표준편차
* np.mean(train_input, axis=0) # array타입 데이터([[XX, YY], [XX, YY]])에서 axis=0이면 XX끼리, YY끼리 계산
axis=1이면 [XX,YY] 별로 계산
※ 주의사항
훈련셋에 적용했던 평균과 표준편차로 검증데이터를 표준화해야함

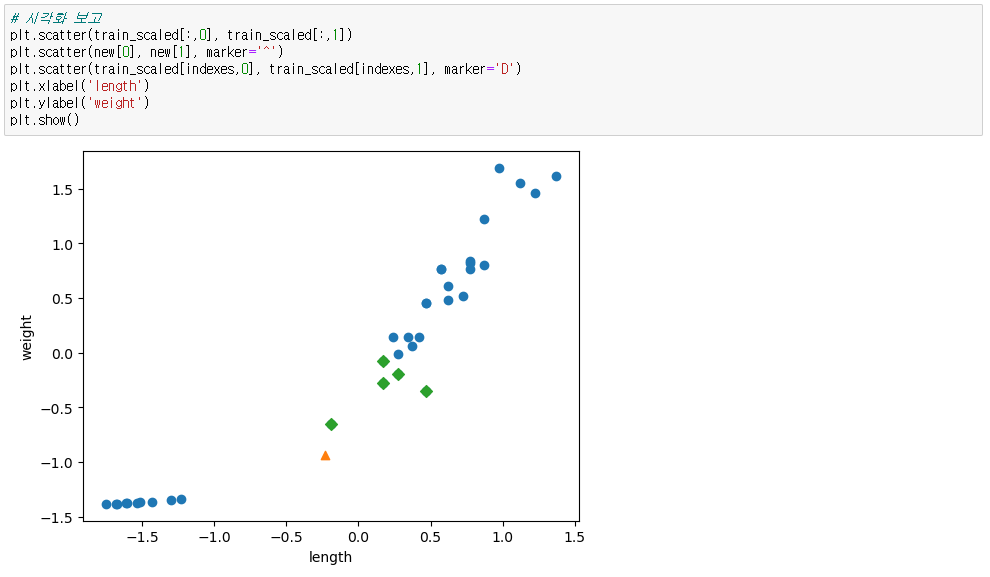
● 결과
★ 사이킷런으로 표준화
from sklearn.metrics import StandardScaler
scaler = SatndardScaler()
scaler.fit_transform(훈련데이터)
scaler.transform(검증데이터)
'데이터 분석' 카테고리의 다른 글
| LinearRegression (0) | 2023.11.17 |
|---|---|
| Regressor(KNeighborsRegressor) (0) | 2023.11.16 |
| 판다스 데이터 전처리 (0) | 2023.11.07 |
| Seaborn (0) | 2023.11.07 |
| Matplotlib 분석(히스토그램, scatter plot, cmap, 파이그래프, boxplot) (0) | 2023.11.06 |



