◆ 데이터 준비

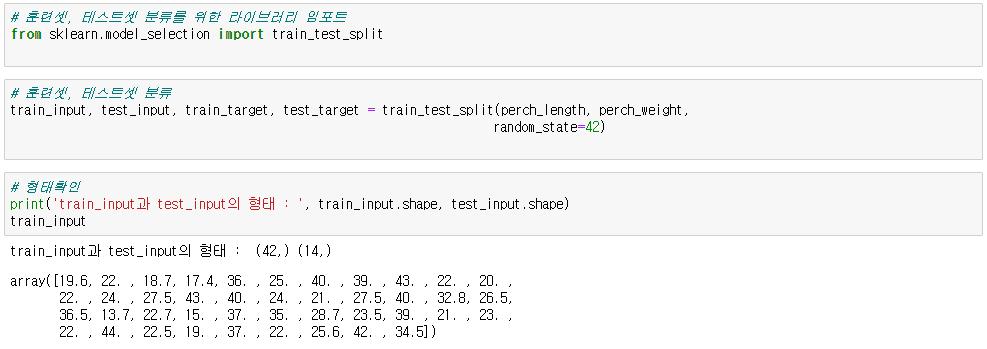
※ reshape
arr.reshape(행,열)
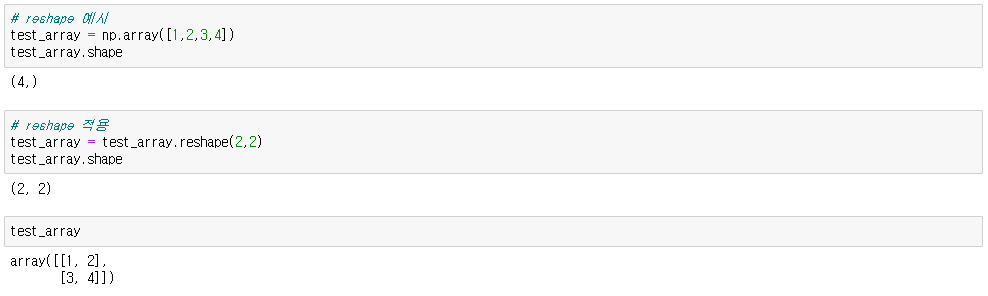
● 데이터에 reshape 적용
* -1로 하면 알아서 해당 개수대로 들어감

◆ KNeighborsRegressor
from sklearn.neighbors import KNeighorsRegressor
knr = KNeighborsRegressor()
knr.fit(독립변수, 종속변수)
knr.score(독립변수, 종속변수)

● 회귀 정확도
- 수치형 결과는 정답과 똑같은 결과가 나오기 힘들고 얼만큼 가깝게 맞췄는지에 대해서도 확인해야함
- MAE, MSE, RMSE 등
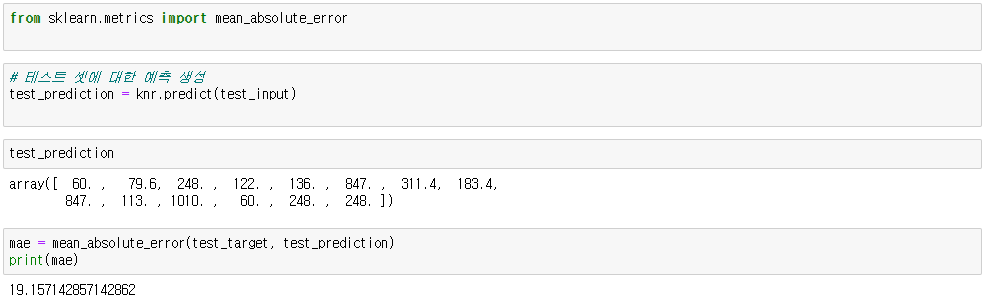
from sklearn.metrics import mean_absolute_error
mean_absolute_error(실제값(정답), 예측값)
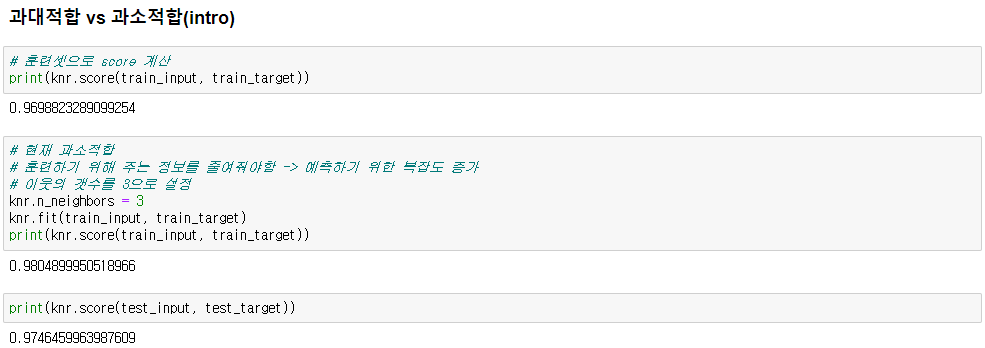
◆ 과대적합 VS 과소적합
* 훈련셋 점수 < 테스트셋 점수 => 과소적합
해결방안 - 복잡도 증가(하이퍼파라미터 튜닝 - n_neighbors를 감소시키기)
* 튜닝 후 테스트셋의 점수가 전보다 감소했어도 모델의 신뢰도가 튜닝후가 더 높음
* 신뢰도 높은 모델 만들기
1) 훈련셋 점수와 테스트셋 점수가 차이가 많이 안나게
2) 훈련셋의 점수가 더 높게
'데이터 분석' 카테고리의 다른 글
| Feature_engineering (0) | 2023.12.12 |
|---|---|
| LinearRegression (0) | 2023.11.17 |
| KNeiborsClassifier (0) | 2023.11.16 |
| 판다스 데이터 전처리 (0) | 2023.11.07 |
| Seaborn (0) | 2023.11.07 |



